#37653 support `default impl` for specialization
this commit implements the second part of the `default impl` feature:
> - a `default impl` need not include all items from the trait
> - a `default impl` alone does not mean that a type implements the trait
The first point allows rustc to compile and run something like this:
```
trait Foo {
fn foo_one(&self) -> &'static str;
fn foo_two(&self) -> &'static str;
}
default impl<T> Foo for T {
fn foo_one(&self) -> &'static str {
"generic"
}
}
struct MyStruct;
fn main() {
assert!(MyStruct.foo_one() == "generic");
}
```
but it shows a proper error if trying to call `MyStruct.foo_two()`
The second point allows a `default impl` to be considered as not implementing the `Trait` if it doesn't implement all the trait items.
The tests provided (in the compile-fail section) should cover all the possible trait resolutions.
Let me know if some tests is missed.
See [referenced ](https://github.com/rust-lang/rust/issues/37653) issue for further info
r? @nikomatsakis
Add std/core::iter::repeat_with
Adds an iterator primitive `repeat_with` which is the "lazy" version of `repeat` but also more flexible since you can build up state with the `FnMut`. The design is mostly taken from `repeat`.
r? @rust-lang/libs
cc @withoutboats, @scottmcm
Add Range[Inclusive]::is_empty
During https://github.com/rust-lang/rfcs/pull/1980, it was discussed that figuring out whether a range is empty was subtle, and thus there should be a clear and obvious way to do it. It can't just be ExactSizeIterator::is_empty (also unstable) because not all ranges are ExactSize -- such as `Range<i64>` and `RangeInclusive<usize>`.
Things to ponder:
- Unless this is stabilized first, this makes stabilizing ExactSizeIterator::is_empty more icky, since this hides that.
- This is only on `Range` and `RangeInclusive`, as those are the only ones where it's interesting. But one could argue that it should be on more for consistency, or on RangeArgument instead.
- The bound on this is PartialOrd, since that works ok (see tests for float examples) and is consistent with `contains`. But ranges like `NAN..=NAN`_are_ kinda weird.
- [x] ~~There's not a real issue number on this yet~~
Document the behaviour of infinite iterators on potentially-computable methods
It’s not entirely clear from the current documentation what behaviour
calling a method such as `min` on an infinite iterator like `RangeFrom`
is. One might expect this to terminate, but in fact, for infinite
iterators, `min` is always nonterminating (at least in the standard
library). This adds a quick note about this behaviour for clarification.
During the RFC, it was discussed that figuring out whether a range is empty was subtle, and thus there should be a clear and obvious way to do it. It can't just be ExactSizeIterator::is_empty (also unstable) because not all ranges are ExactSize -- not even Range<i32> or RangeInclusive<usize>.
`match`ing on an `Option<Ordering>` seems cause some confusion for LLVM; switching to just using comparison operators removes a few jumps from the simple `for` loops I was trying.
Implement TrustedLen for Take<Repeat> and Take<RangeFrom>
This will allow optimization of simple `repeat(x).take(n).collect()` iterators, which are currently not vectorized and have capacity checks.
This will only support a few aggregates on `Repeat` and `RangeFrom`, which might be enough for simple cases, but doesn't optimize more complex ones. Namely, Cycle, StepBy, Filter, FilterMap, Peekable, SkipWhile, Skip, FlatMap, Fuse and Inspect are not marked `TrustedLen` when the inner iterator is infinite.
Previous discussion can be found in #47082
r? @alexcrichton
Add filtering options to `rustc_on_unimplemented`
- Add filtering options to `rustc_on_unimplemented` for local traits, filtering on `Self` and type arguments.
- Add a way to provide custom notes.
- Tweak binops text.
- Add filter to detect wether `Self` is local or belongs to another crate.
- Add filter to `Iterator` diagnostic for `&str`.
Partly addresses #44755 with a different syntax, as a first approach. Fixes#46216, fixes#37522, CC #34297, #46806.
Because the last item needs special handling, it seems that LLVM has trouble canonicalizing the loops in external iteration. With the override, it becomes obvious that the start==end case exits the loop (as opposed to the one *after* that exiting the loop in external iteration).
It’s not entirely clear from the current documentation what behaviour
calling a method such as `min` on an infinite iterator like `RangeFrom`
is. One might expect this to terminate, but in fact, for infinite
iterators, `min` is always nonterminating (at least in the standard
library). This adds a quick note about this behaviour for clarification.
show in docs whether the return type of a function impls Iterator/Read/Write
Closes#25928
This PR makes it so that when rustdoc documents a function, it checks the return type to see whether it implements a handful of specific traits. If so, it will print the impl and any associated types. Rather than doing this via a whitelist within rustdoc, i chose to do this by a new `#[doc]` attribute parameter, so things like `Future` could tap into this if desired.
### Known shortcomings
~~The printing of impls currently uses the `where` class over the whole thing to shrink the font size relative to the function definition itself. Naturally, when the impl has a where clause of its own, it gets shrunken even further:~~ (This is no longer a problem because the design changed and rendered this concern moot.)
The lookup currently just looks at the top-level type, not looking inside things like Result or Option, which renders the spotlights on Read/Write a little less useful:
<details><summary>`File::{open, create}` don't have spotlight info (pic of old design)</summary>
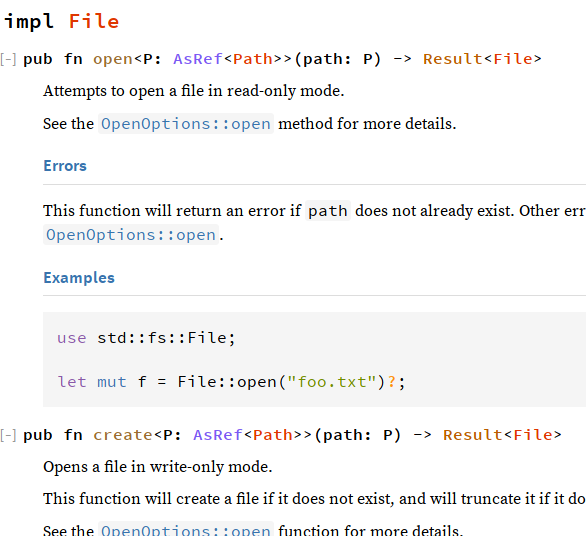
</details>
All three of the initially spotlighted traits are generically implemented on `&mut` references. Rustdoc currently treats a `&mut T` reference-to-a-generic as an impl on the reference primitive itself. `&mut Self` counts as a generic in the eyes of rustdoc. All this combines to create this lovely scene on `Iterator::by_ref`:
<details><summary>`Iterator::by_ref` spotlights Iterator, Read, and Write (pic of old design)</summary>
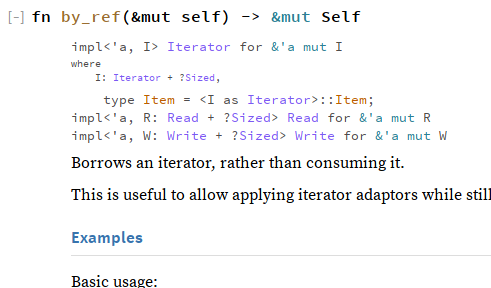
</details>
{kind=link}
{kind=link}