Implement advance_by, advance_back_by for iter::Chain
Part of #77404.
This PR does two things:
- implement `Chain::advance[_back]_by` in terms of `advance[_back]_by` on `self.a` and `advance[_back]_by` on `self.b`
- change `Chain::nth[_back]` to use `advance[_back]_by` on `self.a` and `nth[_back]` on `self.b`
This ensures that `Chain::nth` can take advantage of an efficient `nth` implementation on the second iterator, in case it doesn't implement `advance_by`.
cc `@scottmcm` in case you want to review this
Add Iterator::advance_by and DoubleEndedIterator::advance_back_by
This PR adds the iterator method
```rust
fn advance_by(&mut self, n: usize) -> Result<(), usize>
```
that advances the iterator by `n` elements, returning `Ok(())` if this succeeds or `Err(len)` if the length of the iterator was less than `n`.
Currently `Iterator::nth` is the method to override for efficiently advancing an iterator by multiple elements at once. `advance_by` is superior for this purpose because
- it's simpler to implement: instead of advancing the iterator and producing the next element you only need to advance the iterator
- it composes better: iterators like `Chain` and `FlatMap` can implement `advance_by` in terms of `advance_by` on their inner iterators, but they cannot implement `nth` in terms of `nth` on their inner iterators (see #60395)
- the default implementation of `nth` can trivially be implemented in terms of `advance_by` and `next`, which this PR also does
This PR also adds `DoubleEndedIterator::advance_back_by` for all the same reasons.
I'll make a tracking issue if it's decided this is worth merging. Also let me know if anything can be improved, this went through several iterations so there might very well still be room for improvement (especially in the doc comments). I've written overrides of these methods for most iterators that already override `nth`/`nth_back`, but those still need tests so I'll add them in a later PR.
cc @cuviper @scottmcm @Amanieu
Add doc alias for iterator fold
fold is known in python and javascript as reduce,
not sure about inject but it was written in doc there.
This was my first confusion when coming into rust, I somehow cannot find where is reduce, sometimes I still forget that it is known as `fold`.
It's possible for method resolution to pick this method over a lower
priority stable method, causing compilation errors. Since this method
is permanently unstable, give it a name that is very unlikely to be used
in user code.
Use ops::ControlFlow in rustc_data_structures::graph::iterate
Since I only know about this because you mentioned it,
r? @ecstatic-morse
If we're not supposed to use new `core` things in compiler for a while then feel free to close, but it felt reasonable to merge the two types since they're the same, and it might be convenient for people to use `?` in their traversal code.
(This doesn't do the type parameter swap; NoraCodes has signed up to do that one.)
I believe the documentation is currently a little misleading.
For example, in the docs for `filter()`:
> If the closure returns `false`, it will try again, and call the closure on
> the next element, seeing if it passes the test.
This kind of implies that if the closure returns true then we *don't* "try
again" and no further elements are considered. In actuality that's not the
case, every element is tried regardless of what happened with the previous
element.
This change tries to clarify that by removing the uses of "try again"
altogether.
specialize some collection and iterator operations to run in-place
This is a rebase and update of #66383 which was closed due inactivity.
Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that.
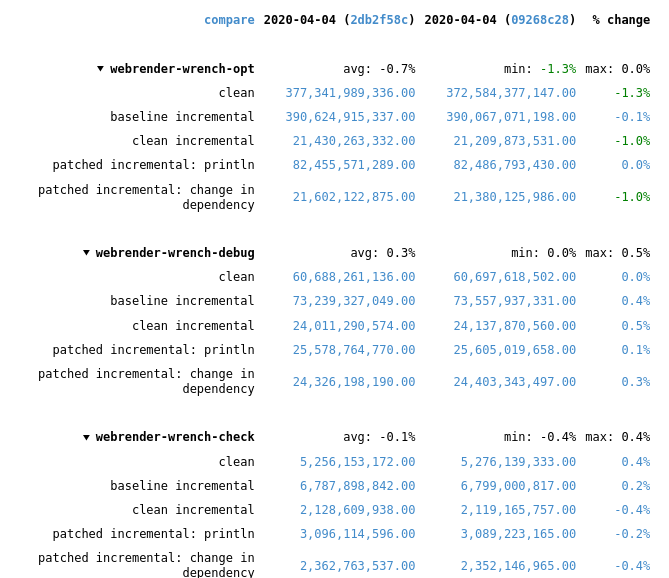
In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools.
## What was changed
* `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits
* `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices.
* A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained.
* A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs.
* To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place.
* `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this.
## In-place collectible adapters
* `Map`
* `MapWhile`
* `Filter`
* `FilterMap`
* `Fuse`
* `Skip`
* `SkipWhile`
* `Take`
* `TakeWhile`
* `Enumerate`
* `Zip` (left hand side only, `Copy` types only)
* `Peek`
* `Scan`
* `Inspect`
## Concerns
`vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected.
If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case.
## Possible followup work
* split liballoc/vec.rs to remove `ignore-tidy-filelength`
* try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see #69187 )
* improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use
* allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
rustdoc: do not use plain summary for trait impls
Fixes#38386.
Fixes#48332.
Fixes#49430.
Fixes#62741.
Fixes#73474.
Unfortunately this is not quite ready to go because the newly-working links trigger a bunch of linkcheck failures. The failures are tough to fix because the links are resolved relative to the implementor, which could be anywhere in the module hierarchy.
(In the current docs, these links end up rendering as uninterpreted markdown syntax, so I don't think these failures are any worse than the status quo. It might be acceptable to just add them to the linkchecker whitelist.)
Ideally this could be fixed with intra-doc links ~~but it isn't working for me: I am currently investigating if it's possible to solve it this way.~~ Opened #73829.
EDIT: This is now ready!
{kind=link}