Refactor the partitioning module to make it easier to introduce new algorithms
I've split the `librustc_mir::monomorphize::partitioning` module into a few files and introduced a `Partitioner` trait which allows us to decouple the partitioning algorithm from the code which integrates it into the query system. This should allow us to introduce new partitioning algorithms much more easily. I've also gone ahead and added a `-Z` flag to control which algorithm is used (currently there is only the `default`).
I left a few comments in places where things might be improved further.
r? @pnkfelix cc @rust-lang/wg-incr-comp
Bump LLVM on CI to 10.0.0
This PR bumps the LLVM version we use on our macOS and Windows CI to 10.0.0, fixing a breakage we noticed today:
```
2020-08-25T14:24:28.5939568Z FAILED: lib/Support/CMakeFiles/LLVMSupport.dir/AMDGPUMetadata.cpp.obj
2020-08-25T14:24:28.5940317Z D:\a\rust\rust\build\bootstrap\debug\sccache-plus-cl.exe /nologo -TP -DGTEST_HAS_RTTI=0 -DUNICODE -D_CRT_NONSTDC_NO_DEPRECATE -D_CRT_NONSTDC_NO_WARNINGS -D_CRT_SECURE_NO_DEPRECATE -D_CRT_SECURE_NO_WARNINGS -D_HAS_EXCEPTIONS=0 -D_SCL_SECURE_NO_DEPRECATE -D_SCL_SECURE_NO_WARNINGS -D_UNICODE -D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_LIMIT_MACROS -Ilib\Support -ID:\a\rust\rust\src\llvm-project\llvm\lib\Support -Iinclude -ID:\a\rust\rust\src\llvm-project\llvm\include -nologo -MT -Brepro --target=x86_64-pc-windows-msvc /Zc:inline /Zc:strictStrings /Oi /Zc:rvalueCast /Brepro /W4 -Wextra -Wno-unused-parameter -Wwrite-strings -Wcast-qual -Wmissing-field-initializers -Wno-noexcept-type -Wno-comment /Gw /MT /O2 /Ob2 -UNDEBUG -std:c++14 /EHs-c- /GR- /showIncludes /Folib\Support\CMakeFiles\LLVMSupport.dir\AMDGPUMetadata.cpp.obj /Fdlib\Support\CMakeFiles\LLVMSupport.dir\LLVMSupport.pdb -c D:\a\rust\rust\src\llvm-project\llvm\lib\Support\AMDGPUMetadata.cpp
2020-08-25T14:24:28.5940861Z clang-cl: warning: argument unused during compilation: '-Brepro' [-Wunused-command-line-argument]
2020-08-25T14:24:28.5941076Z clang-cl: warning: argument unused during compilation: '-Brepro' [-Wunused-command-line-argument]
2020-08-25T14:24:28.5941321Z In file included from D:\a\rust\rust\src\llvm-project\llvm\lib\Support\AMDGPUMetadata.cpp:15:
2020-08-25T14:24:28.5941545Z In file included from D:\a\rust\rust\src\llvm-project\llvm\include\llvm/ADT/Twine.h:12:
2020-08-25T14:24:28.5941774Z In file included from D:\a\rust\rust\src\llvm-project\llvm\include\llvm/ADT/SmallVector.h:16:
2020-08-25T14:24:28.5942016Z In file included from D:\a\rust\rust\src\llvm-project\llvm\include\llvm/ADT/iterator_range.h:21:
2020-08-25T14:24:28.5942257Z In file included from C:\Program Files (x86)\Microsoft Visual Studio\2019\Enterprise\VC\Tools\MSVC\14.27.29110\include\iterator:9:
2020-08-25T14:24:28.5942542Z C:\Program Files (x86)\Microsoft Visual Studio\2019\Enterprise\VC\Tools\MSVC\14.27.29110\include\yvals_core.h(494,2): error: STL1000: Unexpected compiler version, expected Clang 10.0.0 or newer.
```
I uploaded both the new tarballs to our mirrors bucket.
Introduce expect snapshot testing library into rustc
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:
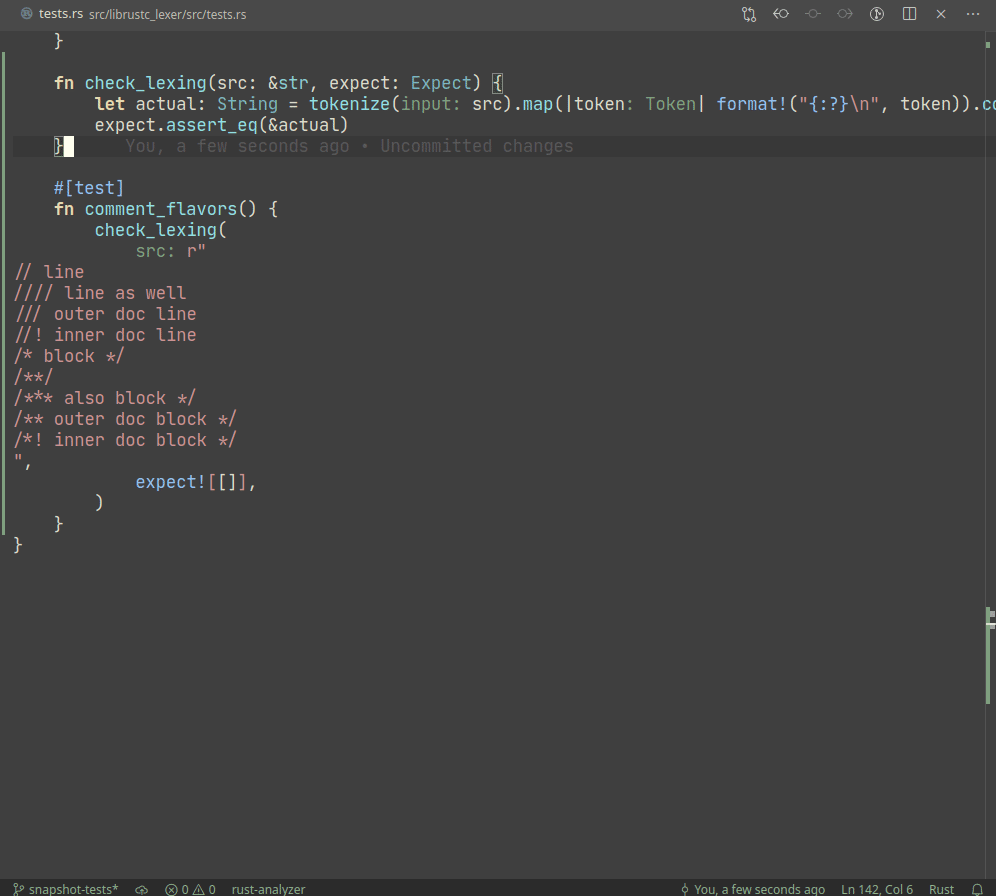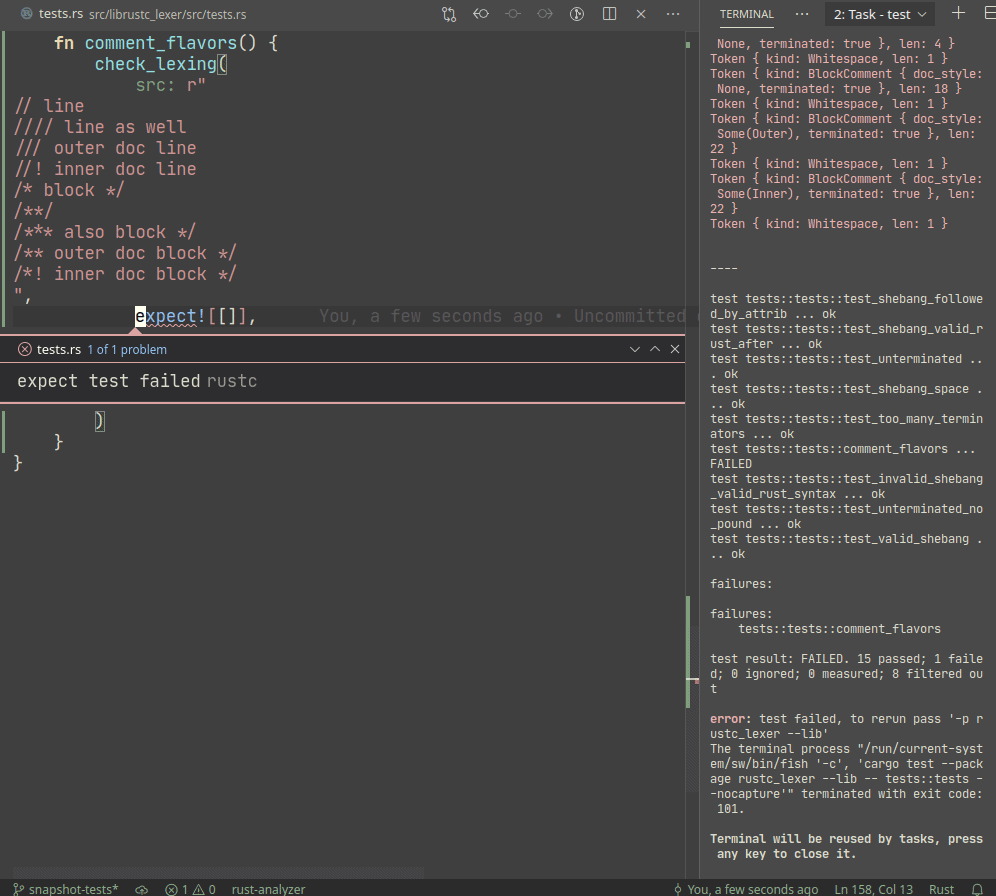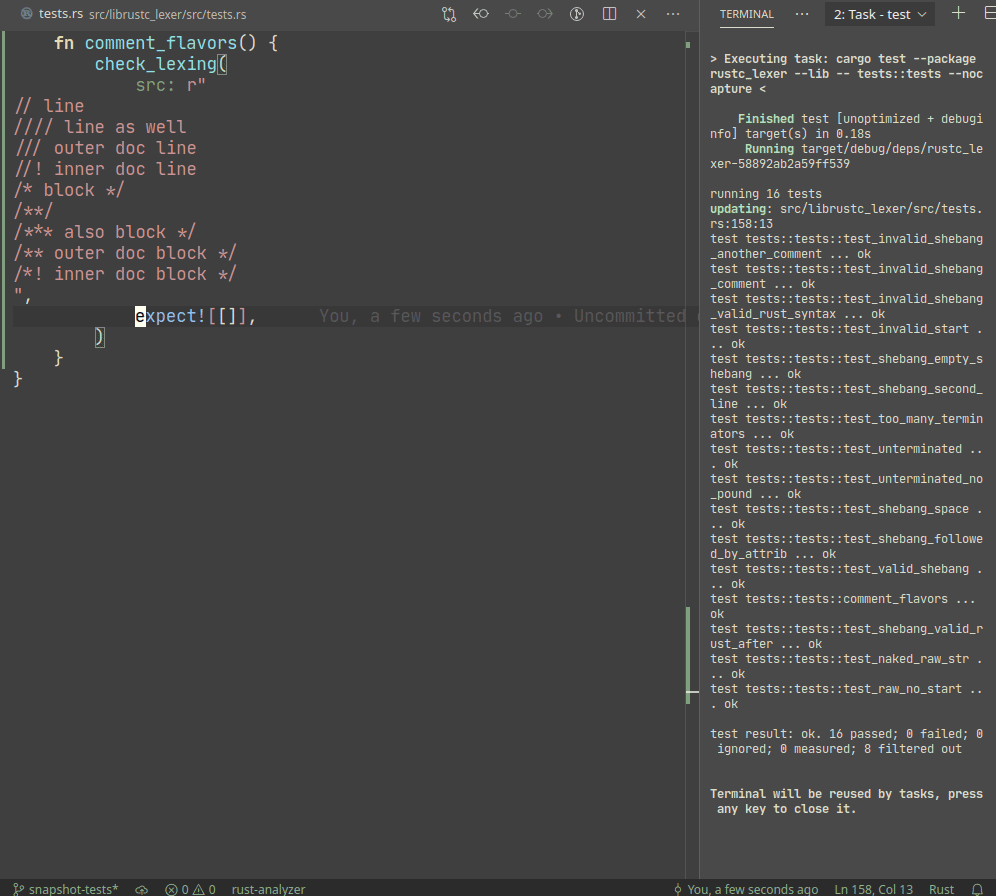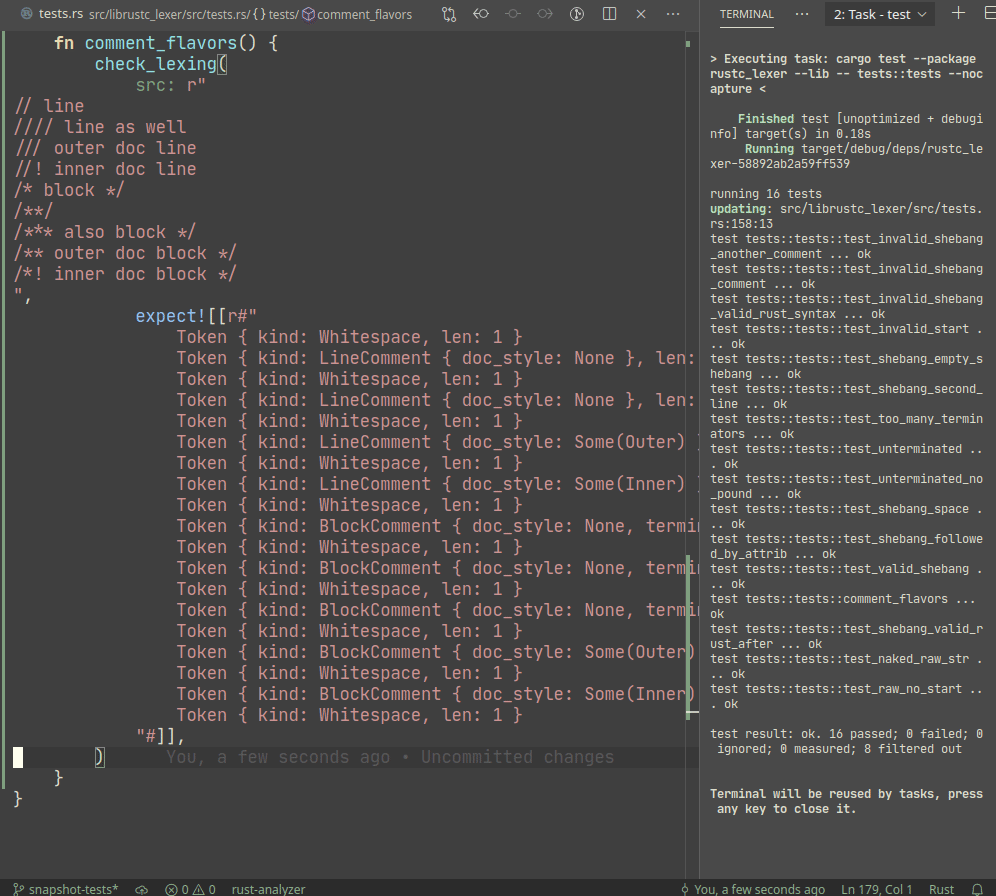
A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See rust-analyzer/rust-analyzer#5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
hir: consistent use and naming of lang items
This PR adjusts the naming of various lang items so that they are consistent and don't include prefixes containing the target or "LangItem". In addition, lang item variants are no longer exported from the `lang_items` module.
This is certainly subjective and while I think this is an improvement, if many in the team don't then we can just close this.
Fix windows-gnu host cross-compilation
Fixes https://github.com/rust-lang/rust/issues/64218
Also turns out it's faster to run Linux virtual machine on Windows and cross-compile `./x.py dist` than doing it on Windows directly...
I would like to propose these two simple methods for stabilization:
- Knowing that a range is exhaused isn't otherwise trivial
- Clippy would like to suggest them, but had to do extra work to disable that path <https://github.com/rust-lang/rust-clippy/issues/3807> because they're unstable
- These work on `PartialOrd`, consistently with now-stable `contains`, and are thus more general than iterator-based approaches that need `Step`
- They've been unchanged for some time, and have picked up uses in the compiler
- Stabilizing them doesn't block any future iterator-based is_empty plans, as the inherent ones are preferred in name resolution
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:

A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See https://github.com/rust-analyzer/rust-analyzer/pull/5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
Add some timing info to rustdoc
There are various improvements, but the main one is to time each pass
that rustdoc performs (`rustdoc::passes`).
Before, these were the top five timings for `cargo doc` on the cargo
repository:
```
+---------------------------------+-----------+-----------------+----------+------------+
| Item | Self time | % of total time | Time | Item count |
+---------------------------------+-----------+-----------------+----------+------------+
| <unknown> | 854.70ms | 20.888 | 2.47s | 744823 |
+---------------------------------+-----------+-----------------+----------+------------+
| expand_crate | 795.29ms | 19.436 | 848.00ms | 1 |
+---------------------------------+-----------+-----------------+----------+------------+
| metadata_decode_entry | 256.73ms | 6.274 | 279.49ms | 518344 |
+---------------------------------+-----------+-----------------+----------+------------+
| resolve_crate | 240.56ms | 5.879 | 242.86ms | 1 |
+---------------------------------+-----------+-----------------+----------+------------+
| hir_lowering | 146.79ms | 3.587 | 146.79ms | 1 |
+---------------------------------+-----------+-----------------+----------+------------+
```
Now the timings are:
```
+---------------------------------+-----------+-----------------+----------+------------+
| Item | Self time | % of total time | Time | Item count |
+---------------------------------+-----------+-----------------+----------+------------+
| <unknown> | 1.40s | 22.662 | 3.73s | 771430 |
+---------------------------------+-----------+-----------------+----------+------------+
| collect-trait-impls | 1.34s | 21.672 | 2.87s | 1 |
+---------------------------------+-----------+-----------------+----------+------------+
| expand_crate | 1.21s | 19.577 | 1.28s | 1 |
+---------------------------------+-----------+-----------------+----------+------------+
| build extern trait impl | 704.66ms | 11.427 | 1.07s | 21893 |
+---------------------------------+-----------+-----------------+----------+------------+
| metadata_decode_entry | 354.84ms | 5.754 | 391.81ms | 544919 |
+---------------------------------+-----------+-----------------+----------+------------+
```
The goal is to help me debug regressions like https://github.com/rust-lang/rust/pull/74518#issuecomment-661498214 (currently I have _no_ idea what could have gone wrong).
r? @eddyb or @Mark-Simulacrum
This commit adjusts the naming of various lang items so that they are
consistent and don't include prefixes containing the target or
"LangItem". In addition, lang item variants are no longer exported from
the `lang_items` module.
Signed-off-by: David Wood <david@davidtw.co>
Report an ambiguity if both modules and primitives are in scope for intra-doc links
Closes https://github.com/rust-lang/rust/issues/75381
- Add a new `prim@` disambiguator, since both modules and primitives are in the same namespace
- Refactor `report_ambiguity` into a closure
Additionally, I noticed that rustdoc would previously allow `[struct@char]` if `char` resolved to a primitive (not if it had a DefId). I fixed that and added a test case.
I also need to update libstd to use `prim@char` instead of `type@char`. If possible I would also like to refactor `ambiguity_error` to use `Disambiguator` instead of its own hand-rolled match - that ran into issues with `prim@` (I updated one and not the other) and it would be better for them to be in sync.
publish-toolstate: show more context on HTTP error
The default display for HTTPError in Python does not include the request body. For GitHub API, the body includes more details about the error (like rate limiting). This could help diagnosing errors like this: https://github.com/rust-lang/rust/pull/75815#issuecomment-678798158
- Add a new `prim@` disambiguator, since both modules and primitives are
in the same namespace
- Refactor `report_ambiguity` into a closure
Additionally, I noticed that rustdoc would previously allow
`[struct@char]` if `char` resolved to a primitive (not if it had a
DefId). I fixed that and added a test case.
Fix intra-doc links for associated items
@Manishearth and I found that links of the following sort are broken:
```rust
$ cat str_from.rs
/// [`String::from`]
pub fn foo() {}
$ rustdoc str_from.rs
warning: `[String::from]` cannot be resolved, ignoring it.
--> str_from.rs:4:6
|
4 | /// [`String::from`]
| ^^^^^^^^^^^^^^ cannot be resolved, ignoring
```
It turns out this is because the current implementation only looks at inherent impls (`impl Bar {}`) and traits _for the item being documented_. Note that this is not the same as the item being _linked_ to. So this code would work:
```rust
pub trait T1 {
fn method();
}
pub struct S;
impl T1 for S {
/// [S::method] on method
fn method() {}
}
```
but putting the documentation on `trait T1` would not.
~~I realized that writing it up that my fix is only partially correct: It removes the inherent impls code when it should instead remove the `trait_item` code.~~ Fixed.
Additionally, I discovered while writing this there is some ambiguity: you could have multiple methods with the same name, but for different traits:
```rust
pub trait T1 {
fn method();
}
pub trait T2 {
fn method();
}
/// See [S::method]
pub struct S;
```
Rustdoc should give an ambiguity error here, but since there is currently no way to disambiguate the traits (https://github.com/rust-lang/rust/issues/74563) it does not (https://github.com/rust-lang/rust/pull/74489#issuecomment-673878404).
There is a _third_ ambiguity that pops up: What if the trait is generic and is implemented multiple times with different generic parameters? In this case, my fix does not do very well: it thinks there is only one trait instantiated and links to that trait:
```
/// [`String::from`] -- this resolves to https://doc.rust-lang.org/nightly/alloc/string/struct.String.html#method.from
pub fn foo() {}
```
However, every `From` implementation has a method called `from`! So the browser picks a random one. This is not the desired behavior, but it's not clear how to avoid it.
To be consistent with the rest of intra-doc links, this only resolves associated items from traits that are in scope. This required changes to rustc_resolve to work cross-crate; the relevant commits are prefixed with `resolve: `. As a bonus, considering only traits in scope is slightly faster. To avoid re-calculating the traits over and over, rustdoc uses a cache to store the traits in scope for a given module.
Provide better spans for the match arm without tail expression
Resolves#75418.
Applied the same logic in the `if`-`else` type mismatch case.
r? @estebank
stabilize ptr_offset_from
This stabilizes ptr::offset_from, and closes https://github.com/rust-lang/rust/issues/41079. It also removes the deprecated `wrapping_offset_from`. This function was deprecated 19 days ago and was never stable; given an FCP of 10 days and some waiting time until FCP starts, that leaves at least a month between deprecation and removal which I think is fine for a nightly-only API.
Regarding the open questions in https://github.com/rust-lang/rust/issues/41079:
* Should offset_from abort instead of panic on ZSTs? -- As far as I know, there is no precedent for such aborts. We could, however, declare this UB. Given that the size is always known statically and the check thus rather cheap, UB seems excessive.
* Should there be more methods like this with different restrictions (to allow nuw/nsw, perhaps) or that return usize (like how isize-taking offset is more conveniently done with usize-taking add these days)? -- No reason to block stabilization on that, we can always add such methods later.
Also nominating the lang team because this exposes an intrinsic.
The stabilized method is best described [by its doc-comment](56d4b2d69a/src/libcore/ptr/const_ptr.rs (L227)). The documentation forgot to mention the requirement that both pointers must "have the same provenance", aka "be derived from pointers to the same allocation", which I am adding in this PR. This is a precondition that [Miri already implements](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=a3b9d0a07a01321f5202cd99e9613480) and that, should LLVM ever obtain a `psub` operation to subtract pointers, will likely be required for that operation (following the semantics in [this paper](https://people.mpi-sws.org/~jung/twinsem/twinsem.pdf)).
Use smaller def span for functions
Currently, the def span of a function encompasses the entire function
signature and body. However, this is usually unnecessarily verbose - when we are
pointing at an entire function in a diagnostic, we almost always want to
point at the signature. The actual contents of the body tends to be
irrelevant to the diagnostic we are emitting, and just takes up
additional screen space.
This commit changes the `def_span` of all function items (freestanding
functions, `impl`-block methods, and `trait`-block methods) to be the
span of the signature. For example, the function
```rust
pub fn foo<T>(val: T) -> T { val }
```
now has a `def_span` corresponding to `pub fn foo<T>(val: T) -> T`
(everything before the opening curly brace).
Trait methods without a body have a `def_span` which includes the
trailing semicolon. For example:
```rust
trait Foo {
fn bar();
}
```
the function definition `Foo::bar` has a `def_span` of `fn bar();`
This makes our diagnostic output much shorter, and emphasizes
information that is relevant to whatever diagnostic we are reporting.
We continue to use the full span (including the body) in a few of
places:
* MIR building uses the full span when building source scopes.
* 'Outlives suggestions' use the full span to sort the diagnostics being
emitted.
* The `#[rustc_on_unimplemented(enclosing_scope="in this scope")]`
attribute points the entire scope body.
All of these cases work only with local items, so we don't need to
add anything extra to crate metadata.
Lazy decoding of DefPathTable from crate metadata (non-incremental case)
The is the half of https://github.com/rust-lang/rust/pull/74967 that doesn't touch incremental-related structures.
We are still decoding def path hashes eagerly if we are in incremental mode.
The incremental part of https://github.com/rust-lang/rust/pull/74967 feels hacky, but I'm not qualified enough to suggest improvements. I'll reassign it so someone else once this PR lands.
@Aaron1011, I wasn't asking you to do this split because I wasn't sure that it's feasible (or simple to do).
r? @Aaron1011
{kind=link}