First of all, the lint is specific for type aliases. Second, it turns out the
bounds are not entirely ignored but actually used when accessing associated
types. So change the wording of the lint, and adapt its name to reality.
The lint has never been on stable or beta, so renaming is safe.
Also, tweak the test for ignored type aliases such that replacing the type alias
by a newtype struct leads to a well-formed type definition, and errors when used
the way the type alias is used.
Warn about ignored generic bounds in `for`
This adds a new lint to fix#42181. For consistency and to avoid code duplication, I also moved the existing "bounds in type aliases are ignored" here.
Questions to the reviewer:
* Is it okay to just remove a diagnostic error code like this? Should I instead keep the warning about type aliases where it is? The old code provided a detailed explanation of what's going on when asked, that information is now lost. On the other hand, `span_warn!` seems deprecated (after this patch, it has exactly one user left!).
* Did I miss any syntactic construct that can appear as `for` in the surface syntax? I covered function types (`for<'a> fn(...)`), generic traits (`for <'a> Fn(...)`, can appear both as bounds as as trait objects) and bounds (`for<'a> F: ...`).
* For the sake of backwards compatibility, this adds a warning, not an error. @nikomatsakis suggested an error in https://github.com/rust-lang/rust/issues/42181#issuecomment-306924389, but I feel that can only happen in a new epoch -- right?
Cc @eddyb
in which parentheses are suggested for should-have-been-tuple-patterns
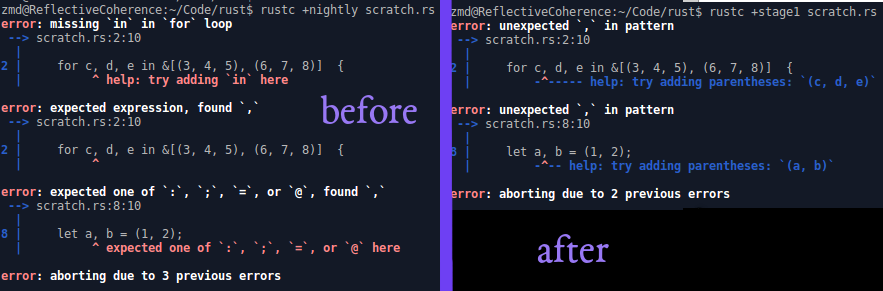
Programmers used to working in some other languages (such as Python or
Go) might expect to be able to destructure values with comma-separated
identifiers but no parentheses on the left side of an assignment.
Previously, the first name in such code would get parsed as a
single-indentifier pattern—recognizing, for example, the
`let a` in `let a, b = (1, 2);`—whereupon we would have a fatal syntax
error on seeing an unexpected comma rather than the expected semicolon
(all the way nearer to the end of `parse_full_stmt`).
Instead, let's look for that comma when parsing the pattern, and if we
see it, make-believe that we're parsing the remaining elements in a
tuple pattern, so that we can suggest wrapping it all in parentheses. We
need to do this in a separate wrapper method called on a "top-level"
pattern, rather than within
`parse_pat` itself, because `parse_pat` gets called recursively to parse
the sub-patterns within a tuple pattern.
~~We could also do this for `match` arms, `if let`, and `while let`, but
we elect not to in this patch, as it seems less likely for users to make
the mistake in those contexts.~~
Resolves#48492.
r? @petrochenkov
Programmers used to working in some other languages (such as Python or
Go) might expect to be able to destructure values with comma-separated
identifiers but no parentheses on the left side of an assignment.
Previously, the first name in such code would get parsed as a
single-indentifier pattern—recognizing, for example, the
`let a` in `let a, b = (1, 2);`—whereupon we would have a fatal syntax
error on seeing an unexpected comma rather than the expected semicolon
(all the way nearer to the end of `parse_full_stmt`).
Instead, let's look for that comma when parsing the pattern, and if we
see it, momentarily make-believe that we're parsing the remaining
elements in a tuple pattern, so that we can suggest wrapping it all in
parentheses. We need to do this in a separate wrapper method called on
the top-level pattern (or `|`-patterns) in a `let` statement, `for`
loop, `if`- or `while let` expression, or match arm rather than within
`parse_pat` itself, because `parse_pat` gets called recursively to parse
the sub-patterns within a tuple pattern.
Resolves#48492.
rustc: Fix ICE with `#[target_feature]` on module
This commit fixes an ICE in rustc when `#[target_feature]` was applied to items
other than functions due to the way the feature was validated.
Also move the check for not having type parameters into ast_validation.
I was not sure what to do with compile-fail/issue-23046.rs: The issue looks like
maybe the bounds actually played a role in triggering the ICE, but that seems
unlikely given that the compiler seems to entirely ignore them. However, I
couldn't find a testcase without the bounds, so I figured the best I could do is
to just remove the bounds and make sure at least that keeps working.
Suggest type for overflowing bin/hex-literals
Fixes#48073
For hexadecimal and binary literals, which overflow, it gives an additional note to the warning message, like in this [comment](https://github.com/rust-lang/rust/issues/48073#issuecomment-365370113).
Additionally it will suggest a type (`X < Y`):
- `iX`: if literal fits in `uX` => `uX`, else => `iY`
- `-iX` => `iY`
- `uX` => `uY`
Exceptions: `isize`, `usize`. I don't think you can make a good suggestion here. The programmer has to figure it out on it's own in this case.
r? @oli-obk
The ExplicitSelf::determine function expects to be able to compare regions.
However, when the compare_self_type error reporting code runs we haven't
resolved bound regions yet. Thus we replace them with free regions first.
Have Vec use slice's implementations of Index<I> and IndexMut<I>
This PR simplifies the implementation of Index and IndexMut on Vec, and in the process enables indexing Vec by any user types that implement SliceIndex.
The stability annotations probably need to be changed, but I wasn't sure of the right way to do that. It also wasn't completely clear to me if this change could break any existing code.
This commit imports the LLD project from LLVM to serve as the default linker for
the `wasm32-unknown-unknown` target. The `binaryen` submoule is consequently
removed along with "binaryen linker" support in rustc.
Moving to LLD brings with it a number of benefits for wasm code:
* LLD is itself an actual linker, so there's no need to compile all wasm code
with LTO any more. As a result builds should be *much* speedier as LTO is no
longer forcibly enabled for all builds of the wasm target.
* LLD is quickly becoming an "official solution" for linking wasm code together.
This, I believe at least, is intended to be the main supported linker for
native code and wasm moving forward. Picking up support early on should help
ensure that we can help LLD identify bugs and otherwise prove that it works
great for all our use cases!
* Improvements to the wasm toolchain are currently primarily focused around LLVM
and LLD (from what I can tell at least), so it's in general much better to be
on this bandwagon for bugfixes and new features.
* Historical "hacks" like `wasm-gc` will soon no longer be necessary, LLD
will [natively implement][gc] `--gc-sections` (better than `wasm-gc`!) which
means a postprocessor is no longer needed to show off Rust's "small wasm
binary size".
LLD is added in a pretty standard way to rustc right now. A new rustbuild target
was defined for building LLD, and this is executed when a compiler's sysroot is
being assembled. LLD is compiled against the LLVM that we've got in tree, which
means we're currently on the `release_60` branch, but this may get upgraded in
the near future!
LLD is placed into rustc's sysroot in a `bin` directory. This is similar to
where `gcc.exe` can be found on Windows. This directory is automatically added
to `PATH` whenever rustc executes the linker, allowing us to define a `WasmLd`
linker which implements the interface that `wasm-ld`, LLD's frontend, expects.
Like Emscripten the LLD target is currently only enabled for Tier 1 platforms,
notably OSX/Windows/Linux, and will need to be installed manually for compiling
to wasm on other platforms. LLD is by default turned off in rustbuild, and
requires a `config.toml` option to be enabled to turn it on.
Finally the unstable `#![wasm_import_memory]` attribute was also removed as LLD
has a native option for controlling this.
[gc]: https://reviews.llvm.org/D42511
{kind=link}