According to <https://caniuse.com/?search=svg%20favicon>,
SVG favicons are supported in everything but Safari.
When I actually try it in Safari, it's downloading all
three favicons, and nothing looks different when I disable
the 16x16 one.
<https://dev.to/masakudamatsu/favicon-nightmare-how-to-maintain-sanity-3al7>,
which is linked from caniuse above, recommends an ico.
However, the reason they recommend it is the apps that
only support /favicon.ico exactly, and rustdoc can't assume
it will be installed to the site root, so it's unfortunately
up to the webmaster to make sure it's set up.
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
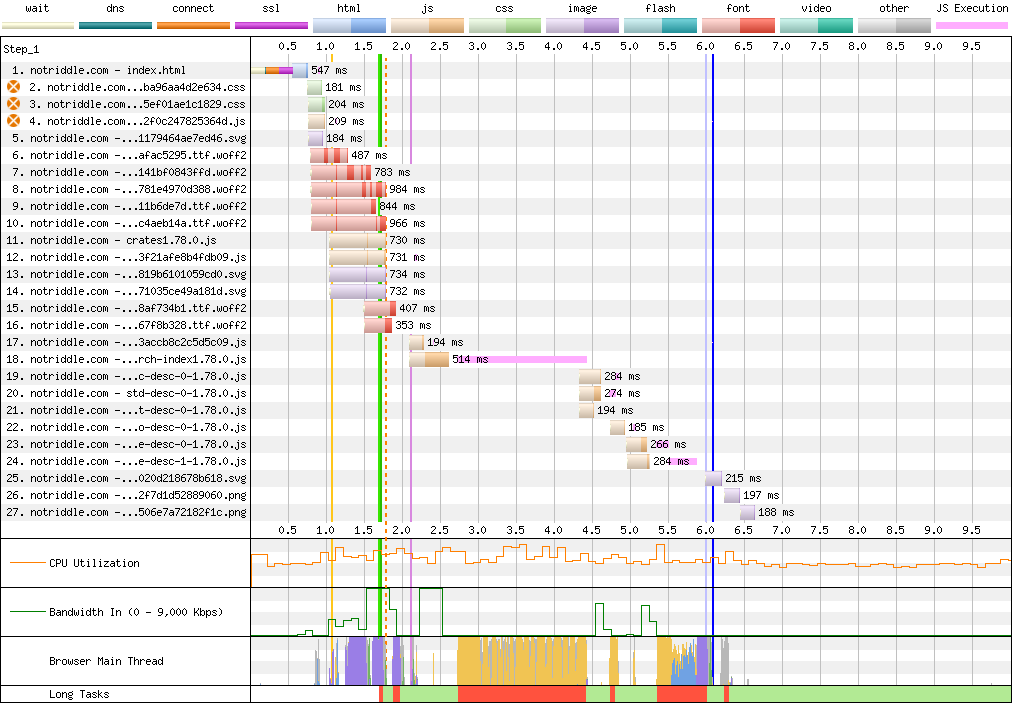
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
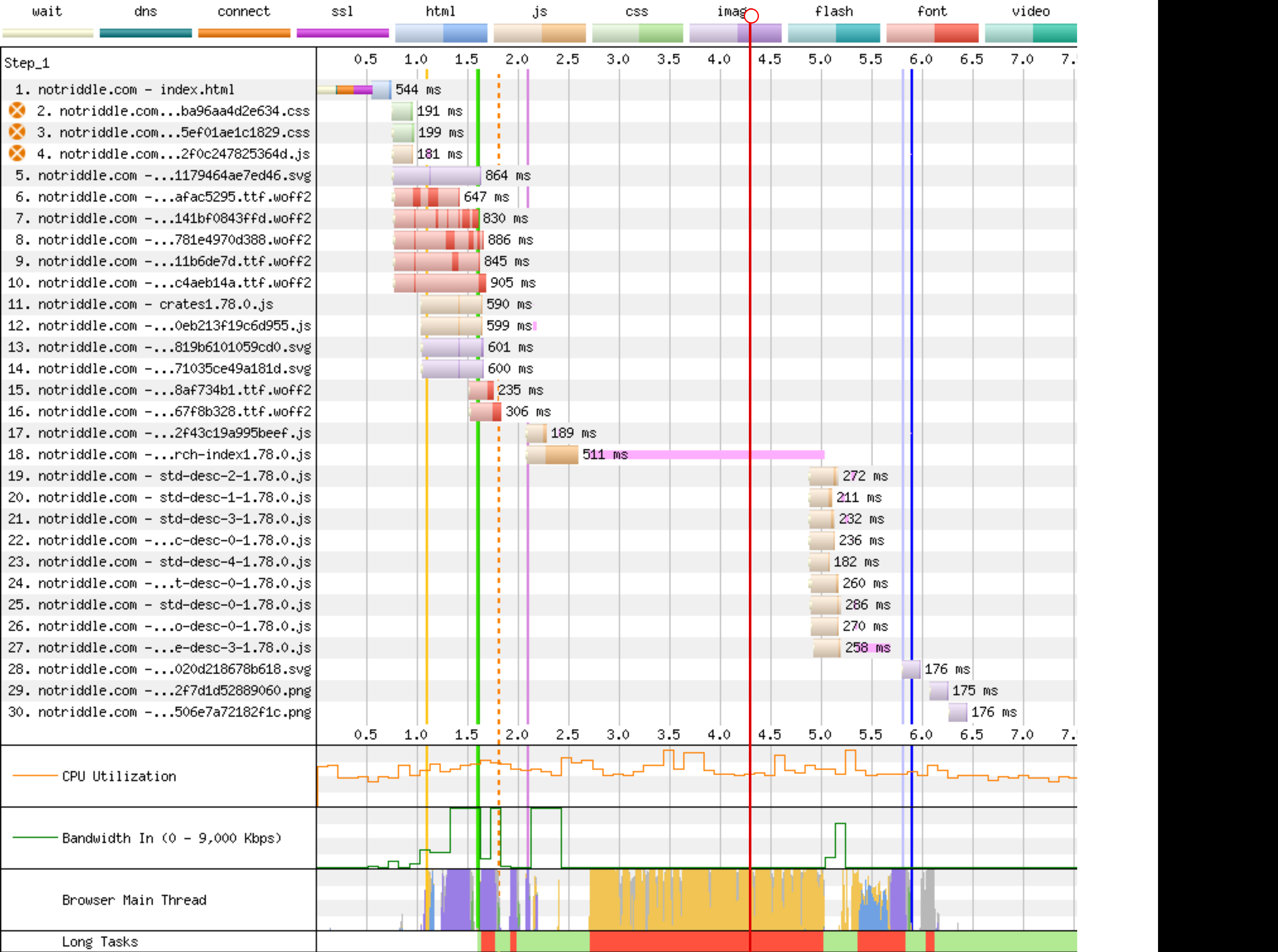
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
Previously, the documentation for a variant appeared after the documentation
for each of its fields. This was inconsistent with structs and unions, and made
little sense on its own; fields are subordinate to variants and should
therefore appear later in the documentation.
This adds a bit more data than "pure sharding" by
including information about which items have no description
at all. This way, it can sort the results, then truncate,
then finally download the description.
With the "e" bitmap: 2380KiB
Without the "e" bitmap: 2364KiB
The descriptions are, on almost all crates[^1], the majority
of the size of the search index, even though they aren't really
used for searching. This makes it relatively easy to separate
them into their own files.
This commit also bumps us to ES8. Out of the browsers we support,
all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted.
Visually mark 👻hidden👻 items with document-hidden-items
Fixes#122485
This adds a 👻 in the item list (much like the 🔒 used for private items), and also shows `#[doc(hidden)]` in the code view, where `pub(crate)` etc gets shown for private items.
This does not do anything for enum variants, if people have ideas. I think we can just show the attribute.
rustdoc-search: depth limit `T<U>` -> `U` unboxing
Profiler output:
https://notriddle.com/rustdoc-html-demo-9/search-unbox-limit/ (the only significant change is that one of the `rust` tests went from 378416ms to 16ms).
This is a performance enhancement aimed at a problem I found while using type-driven search on the Rust compiler. It is caused by [`Interner`], a trait with 41 associated types, many of which recurse back to `Self` again.
This caused search.js to struggle. It eventually terminates, after about 10 minutes of turning my PC into a space header, but it's doing `41!` unifications and that's too slow.
[`Interner`]: https://doc.rust-lang.org/nightly/nightly-rustc/rustc_middle/ty/trait.Interner.html
rustdoc-search: search types by higher-order functions
This feature extends rustdoc with syntax and search index information for searching function pointers and closures (Higher-Order Functions, or HOF). Part of https://github.com/rust-lang/rust/issues/60485
This PR adds two syntaxes: a high-level one for finding any kind of HOF, and a direct implementation of the parenthesized path syntax that Rust itself uses.
## Preview pages
| Query | Results |
|-------|---------|
| [`option<T>, (fnonce (T) -> bool) -> option<T>`][optionfilter] | `Option::filter` |
| [`option<T>, (T -> bool) -> option<T>`][optionfilter2] | `Option::filter` |
Updated chapter of the book: https://notriddle.com/rustdoc-html-demo-9/search-hof/rustdoc/read-documentation/search.html
[optionfilter]: https://notriddle.com/rustdoc-html-demo-9/search-hof/std/vec/struct.Vec.html?search=option<T>%2C+(fnonce+(T)+->+bool)+->+option<T>&filter-crate=std
[optionfilter2]: https://notriddle.com/rustdoc-html-demo-9/search-hof/std/vec/struct.Vec.html?search=option<T>%2C+(T+->+bool)+->+option<T>&filter-crate=std
## Motivation
When type-based search was first landed, it was directly [described as incomplete][a comment].
[a comment]: https://github.com/rust-lang/rust/pull/23289#issuecomment-79437386
Filling out the missing functionality is going to mean adding support for more of Rust's [type expression] syntax, such as references, raw pointers, function pointers, and closures. This PR adds function pointers and closures.
[type expression]: https://doc.rust-lang.org/reference/types.html#type-expressions
There's been demand for something "like Hoogle, but for Rust" expressed a few times [1](https://www.reddit.com/r/rust/comments/y8sbid/is_there_a_website_like_haskells_hoogle_for_rust/) [2](https://users.rust-lang.org/t/rust-equivalent-of-haskells-hoogle/102280) [3](https://internals.rust-lang.org/t/std-library-inclusion-policy/6852/2) [4](https://discord.com/channels/442252698964721669/448238009733742612/1109502307495858216). Some of them just don't realize what functionality already exists ([`Duration -> u64`](https://doc.rust-lang.org/nightly/std/?search=duration%20-%3E%20u64) already works), but a lot of them specifically want to search for higher-order functions like option combinators.
## Guide-level explanation (from the Rustdoc book)
To search for a function that accepts a function as a parameter, like `Iterator::all`, wrap the nested signature in parenthesis, as in [`Iterator<T>, (T -> bool) -> bool`][iterator-all]. You can also search for a specific closure trait, such as `Iterator<T>, (FnMut(T) -> bool) -> bool`, but you need to know which one you want.
[iterator-all]: https://notriddle.com/rustdoc-html-demo-9/search-hof/std/vec/struct.Vec.html?search=Iterator<T>%2C+(T+->+bool)+->+bool&filter-crate=std
## Reference-level description (also from the Rustdoc book)
### Primitives with Special Syntax
<table>
<thead>
<tr>
<th>Shorthand</th>
<th>Explicit names</th>
</tr>
</thead>
<tbody>
<tr><td colspan="2">Before this PR</td></tr>
<tr>
<td><code>[]</code></td>
<td><code>primitive:slice</code> and/or <code>primitive:array</code></td>
</tr>
<tr>
<td><code>[T]</code></td>
<td><code>primitive:slice<T></code> and/or <code>primitive:array<T></code></td>
</tr>
<tr>
<td><code>!</code></td>
<td><code>primitive:never</code></td>
</tr>
<tr>
<td><code>()</code></td>
<td><code>primitive:unit</code> and/or <code>primitive:tuple</code></td>
</tr>
<tr>
<td><code>(T)</code></td>
<td><code>T</code></td>
</tr>
<tr>
<td><code>(T,)</code></td>
<td><code>primitive:tuple<T></code></td>
</tr>
<tr><td colspan="2">After this PR</td></tr>
<tr>
<td><code>(T, U -> V, W)</code></td>
<td><code>fn(T, U) -> (V, W)</code>, Fn, FnMut, and FnOnce</td>
</tr>
</tbody>
</table>
The `->` operator has lower precedence than comma. If it's not wrapped in brackets, it delimits the return value for the function being searched for. To search for functions that take functions as parameters, use parenthesis.
### Search query grammar
```ebnf
ident = *(ALPHA / DIGIT / "_")
path = ident *(DOUBLE-COLON ident) [BANG]
slice-like = OPEN-SQUARE-BRACKET [ nonempty-arg-list ] CLOSE-SQUARE-BRACKET
tuple-like = OPEN-PAREN [ nonempty-arg-list ] CLOSE-PAREN
arg = [type-filter *WS COLON *WS] (path [generics] / slice-like / tuple-like)
type-sep = COMMA/WS *(COMMA/WS)
nonempty-arg-list = *(type-sep) arg *(type-sep arg) *(type-sep) [ return-args ]
generic-arg-list = *(type-sep) arg [ EQUAL arg ] *(type-sep arg [ EQUAL arg ]) *(type-sep)
normal-generics = OPEN-ANGLE-BRACKET [ generic-arg-list ] *(type-sep)
CLOSE-ANGLE-BRACKET
fn-like-generics = OPEN-PAREN [ nonempty-arg-list ] CLOSE-PAREN [ RETURN-ARROW arg ]
generics = normal-generics / fn-like-generics
return-args = RETURN-ARROW *(type-sep) nonempty-arg-list
exact-search = [type-filter *WS COLON] [ RETURN-ARROW ] *WS QUOTE ident QUOTE [ generics ]
type-search = [ nonempty-arg-list ]
query = *WS (exact-search / type-search) *WS
; unchanged parts of the grammar, like the full list of type filters, are omitted
```
## Future direction
### The remaining type expression grammar
As described in https://github.com/rust-lang/rust/pull/118194, this is another step in the type expression grammar: BareFunction, and the function-like mode of TypePath, are now supported.
* RawPointerType and ReferenceType actually are a priority.
* ImplTraitType and TraitObjectType (and ImplTraitTypeOneBound and TraitObjectTypeOneBound) aren't as much of a priority, since they desugar pretty easily.
### Search subtyping and traits
This is the other major factor that makes it less useful than it should be.
* `iterator<result<t>> -> result<t>` doesn't find `Result::from_iter`. You have to search [`intoiterator<result<t>> -> result<t>`](https://notriddle.com/rustdoc-html-demo-9/search-hof/std/vec/struct.Vec.html?search=intoiterator%3Cresult%3Ct%3E%3E%20-%3E%20result%3Ct%3E&filter-crate=std). Nobody's going to search for IntoIterator unless they basically already know about it and don't need the search engine anyway.
* Iterator combinators are usually structs that happen to implement Iterator, like `std::iter::Map`.
To solve these cases, it needs to look at trait implementations, knowing that Iterator is a "subtype of" IntoIterator, and Map is a "subtype of" Iterator, so `iterator -> result` is a subtype of `intoiterator -> result` and `iterator<t>, (t -> u) -> iterator<u>` is a subtype of [`iterator<t>, (t -> u) -> map<t -> u>`](https://notriddle.com/rustdoc-html-demo-9/search-hof/std/vec/struct.Vec.html?search=iterator%3Ct%3E%2C%20(t%20-%3E%20u)%20-%3E%20map%3Ct%20-%3E%20u%3E&filter-crate=std).
This is implemented, in addition to the ML-style one,
because Rust does it. If we don't, we'll never hear the end of it.
This commit also refactors some duplicate parts of the parser
into a dedicated function.
Option::map, for example, looks like this:
option<t>, (t -> u) -> option<u>
This syntax searches all of the HOFs in Rust: traits Fn, FnOnce,
and FnMut, and bare fn primitives.
[rustdoc] Prevent inclusion of whitespace character after macro_rules ident
Discovered this bug randomly when looking at:
We were too eagerly trying to merge tokens that shouldn't be merged together (for example if you have a code comment followed by a code comment, we merge them in one attribute to reduce the DOM size).
r? ``@notriddle``
Diagnostic renaming
Renaming various diagnostic types from `Diagnostic*` to `Diag*`. Part of https://github.com/rust-lang/compiler-team/issues/722. There are more to do but this is enough for one PR.
r? `@davidtwco`
Correctly handle if rustdoc JS script hash changed
It's something that annoyed me for quite some time: I have nightly docs open (for both std and compiler). And often, I don't look at the page for some days. Then when I come back to it, I make a search... except nothing happens. Took me a while to figure out that it was because the hash of one of the JS files we load for the search (either `search.js` or `search-index.js`) was updated in the meantime, preventing the search to be done. To go around it, I added to press `ENTER` to make the form submitted (which would reload the same page but with the correct hashes this time and the search being run).
r? `@notriddle`
It makes the link easier to use in cases in which
the path of the page where it will be embedded is not
known beforehand such as when we generate impls
dynamically from `register_type_impls` method in
`main.js`
Earlier for local primitives we would generate a path
that was relative to the current page depth passed in `cx.current`
. e.g if the current page was `std::simd::prelude::Simd` the
generated path would be `../../primitive.<prim>.html` After this
change the path will first take you to the the wesite root and add
the crate name. e.g. for `std::simd::prelude::Simd` the path now
will be `../../../std/primitive.<prim>.html`
rustdoc: fix and refactor HTML rendering a bit
* refactoring: get rid of a bunch of manual `f.alternate()` branches
* not sure why this wasn't done so already, is this perf-sensitive?
* fix an ICE in debug builds of rustdoc
* rustdoc used to crash on empty outlives-bounds: `where 'a:`
* properly escape const generic defaults
* actually print empty trait and outlives-bounds (doesn't work for cross-crate reexports yet, will fix that at some other point) since they can have semantic significance
* outlives-bounds: forces lifetime params to be early-bound instead of late-bound which is technically speaking part of the public API
* trait-bounds: can affect the well-formedness, consider
* makeshift “const-evaluatable” bounds under `generic_const_exprs`
* bounds to force wf-checking in light of #100041 (quite artificial I know, I couldn't figure out something better), see https://github.com/rust-lang/rust/pull/121160#discussion_r1491563816