Move size assertions for `mir::syntax` types into the same file
A redundant size assertion for `StatementKind` was added in #122937, because the existing assertion was in a different file.
This PR cleans that up, and also moves the `TerminatorKind` assertion into the same file where it belongs, to avoid the same thing happening again.
r? `@nnethercote`
Opaque types have no namespace
Opaques are never referenced by name -- even when we have `type X = impl Sized;`, `X` is the name of the type alias, not the opaque.
Make `suggest_deref_closure_return` more idiomatic/easier to understand
The only functional change here really is just making it not use a fresh type variable for upvars. I'll point that out in the code.
The rest of the changes are just stylistic, because reading this code was really confusing me (variable names were vague, ways of accessing types were unidiomatic, order of operations was kind of strange, etc).
This is stacked on #123989.
r? oli-obk since you approved #122213
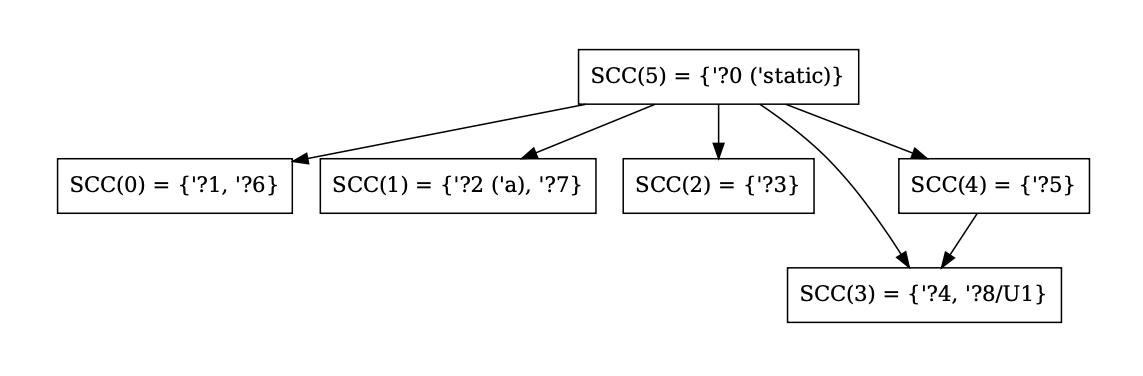
Better graphviz output for SCCs and NLL constraints
This PR modifies the output for `-Z dump-mir-graphviz=yes`. Specifically, it changes the output of the files `.-------.nll.0.regioncx.all.dot` and `nll.0.regioncx.scc.dot` to be easier to read and contain some information that helped me during debugging. In particular:
- SCC indices are contracted to `SCC(n)` instead of `ConstraintSccIndex(n)` to compress the nodes
- SCC regions are in `{}` rather than `[]` (controversial since they are technically ordered by index, but I figured they're more sets than arrays conceptually since they're equivalence classes).
- For regions in other universes than the root, also show the region universe (as ?8/U1)
- For regions with external names, show the external name in parenthesis
- For the region graph where edges are locations, render the All variant of the enum without the file since it's extremely long and often destroys the rendering
- For region graph edge annotations for single locations, remove the wrapping around the Location variant and just add its contents since this can be unambiguously done
Example output (from the function `foo()` of `tests/ui/error-codes/E0582.rs`) for an SCC graph:
...and for the constraints:
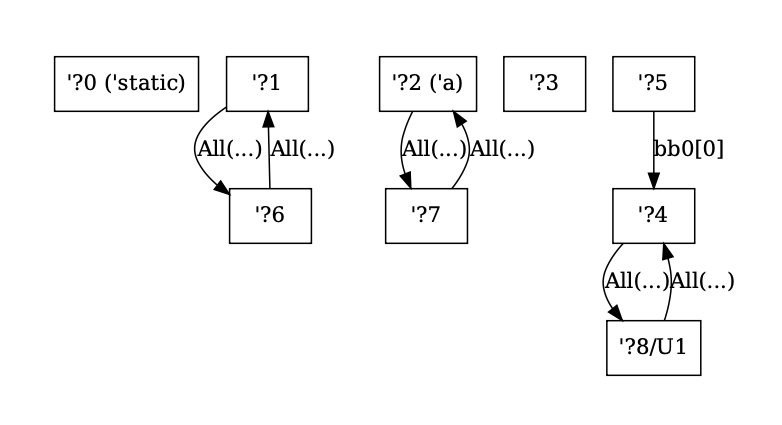
This PR also gives `UniverseIndex`es the `is_root()` method since this is now an operation that happens three times in the borrowck crate.
Update ar_archive_writer to 0.2.0
This adds a whole bunch of tests checking for any difference with llvm's archive writer. It also fixes two mistakes in the porting from C++ to Rust. The first one causes a divergence for Mach-O archives which may or may not be harmless. The second will definitively cause issues, but only applies to thin archives, which rustc currently doesn't create.
Correct usage note on OpenOptions::append()
This PR aims to correct the following usage note in `OpenOptions::append()`, which currently contains misleading information:
> One maybe obvious note when using append-mode: make sure that all data that belongs together is written to the file in one operation. This can be done by concatenating strings before passing them to [write()](https://doc.rust-lang.org/std/io/trait.Write.html#tymethod.write), or using a buffered writer (with a buffer of adequate size), and calling [flush()](https://doc.rust-lang.org/std/io/trait.Write.html#tymethod.flush) when the message is complete.
The above is misleading because, despite appearances, neither concatenating data before passing it to `write()`, nor delaying writes using `BufWriter`, ensures atomicity. `File::write()`, as well as the underlying `write(2)` system call, makes no guarantees that the data passed to it will be written out in full. It is allowed to write out only a part of the data, and has a return value that tells you how much it has written, at which point it has already returned and modified the file with partial data. Given this limitation, the only way to ensure atomicity of appends is through external locking.
Attempting to ensure atomicity by issuing data in a single `write()` is a footgun often stumbled upon by beginners, which shouldn't be advertised in the docs. The worst thing about the footgun is that it *appears* to work at first, only failing when the string becomes sufficiently large, or when some internal properties of the output file descriptor change (e.g. it is switched from regular file to a special file that talks to a socket or TTY), making it accept smaller writes. Additionally, the suggestion to use `BufWriter` skims over the issue of buffer sizes, as well as the fact that `BufWriter::flush()` contains a *loop* that can happily issue multiple writes. This loop is completely opaque to the caller, so you can't even assert atomicity after-the-fact.
The PR makes the following changes:
* removes the paragraph that suggests concatenating strings to pass them to `write()` for atomicity or using `BufWriter`
* adds a paragraph explaining why attempting to use `write()` to append atomically is not a good idea.
Implement syntax for `impl Trait` to specify its captures explicitly (`feature(precise_capturing)`)
Implements `impl use<'a, 'b, T, U> Sized` syntax that allows users to explicitly list the captured parameters for an opaque, rather than inferring it from the opaque's bounds (or capturing *all* lifetimes under 2024-edition capture rules). This allows us to exclude some implicit captures, so this syntax may be used as a migration strategy for changes due to #117587.
We represent this list of captured params as `PreciseCapturingArg` in AST and HIR, resolving them between `rustc_resolve` and `resolve_bound_vars`. Later on, we validate that the opaques only capture the parameters in this list.
We artificially limit the feature to *require* mentioning all type and const parameters, since we don't currently have support for non-lifetime bivariant generics. This can be relaxed in the future.
We also may need to limit this to require naming *all* lifetime parameters for RPITIT, since GATs have no variance. I have to investigate this. This can also be relaxed in the future.
r? `@oli-obk`
Tracking issue:
- https://github.com/rust-lang/rust/issues/123432
Implement syntax for `impl Trait` to specify its captures explicitly (`feature(precise_capturing)`)
Implements `impl use<'a, 'b, T, U> Sized` syntax that allows users to explicitly list the captured parameters for an opaque, rather than inferring it from the opaque's bounds (or capturing *all* lifetimes under 2024-edition capture rules). This allows us to exclude some implicit captures, so this syntax may be used as a migration strategy for changes due to #117587.
We represent this list of captured params as `PreciseCapturingArg` in AST and HIR, resolving them between `rustc_resolve` and `resolve_bound_vars`. Later on, we validate that the opaques only capture the parameters in this list.
We artificially limit the feature to *require* mentioning all type and const parameters, since we don't currently have support for non-lifetime bivariant generics. This can be relaxed in the future.
We also may need to limit this to require naming *all* lifetime parameters for RPITIT, since GATs have no variance. I have to investigate this. This can also be relaxed in the future.
r? `@oli-obk`
Tracking issue:
- https://github.com/rust-lang/rust/issues/123432
threads: keep track of why we are blocked, and sanity-check that when waking up
Also remove support for condvars blocked on rwlocks, as that was no longer used.
Disable two debuginfo tests failing under the future GDB 15 release
As seen in #123960, it seems two of our debuginfo tests started failing on gdb 15, which is also already in use in the `x86_64-gnu-llvm-18` builder: CI will randomly start to fail whenever this cached docker image expires.
This PR disables the following two tests under gdb 15+, to prevent future CI failures.
- `tests/debuginfo/include_string.rs`
- `tests/debuginfo/vec-slices.rs`
This seems very much related to https://sourceware.org/bugzilla/show_bug.cgi?id=30330 and https://sourceware.org/bugzilla/show_bug.cgi?id=31517 -- and I just now saw #122751 as well, where one of these bugzilla issues and one of the two test failures here was previously mentioned.
I don't know whether these are unexpected gdb changes, or if we need to change our tests as it seems some of the gdb changes are definitely intentional, so I'll just cc `@rust-lang/wg-debugging` and `@tromey.`
(In the same area, `tests/debuginfo/unsized.rs` was previously disabled due to https://sourceware.org/bugzilla/show_bug.cgi?id=30330. This issue has been fixed but I don't believe our test passes, so it's in the same boat as the 2 above regarding whether this test is expected to work or needs changes as well)
r? wg-debugging
I've confirmed this is enough to have CI pass on gdb 15 with the llvm 18 builder.
internal : redesign rust-analyzer::config
This PR aims to cover the infrastructural requirements for the `rust-analyzer.toml` ( #13529 ) issue. This means, that
1. We no longer have a single config base. The once single `ConfigData` has been divided into 4 : A tree of `.ratoml` files, a set of configs coming from the client ( this is what was called before the `CrateData` except that now values do not default to anything when they are not defined) , a set of configs that will reflect what the contents of a `ratoml` file defined in user's config directory ( e.g `~/.config/rust-analyzer/.rust-analyzer.toml` and finally a tree root that is populated by default values only.
2. Configs have also been divided into 3 different blocks : `global` , `local` , `client`. The current status of a config may change until #13529 got merged.
Once again many thanks to `@cormacrelf` for doing all the serde work.
Trait predicates for types which have errors may still
evaluate to OK leading to downstream ICEs. Now we return
a selection error for such types in candidate assembly and
thereby prevent such issues
internal: improve `TokenSet` implementation and add reserved keywords
The current `TokenSet` type represents "A bit-set of `SyntaxKind`s" as a newtype `u128`.
Internally, the flag for each `SyntaxKind` variant in the bit-set is set as the n-th LSB (least significant bit) via a bit-wise left shift operation, where n is the discriminant.
Edit: This is problematic because there's currently ~121 token `SyntaxKind`s, so adding new token kinds for missing reserved keywords increases the number of token `SyntaxKind`s above 128, thus making this ["mask"](7a8374c162/crates/parser/src/token_set.rs (L31-L33)) operation overflow.
~~This is problematic because there's currently 266 SyntaxKinds, so this ["mask"](7a8374c162/crates/parser/src/token_set.rs (L31-L33)) operation silently overflows in release mode.~~
~~This leads to a single flag/bit in the bit-set being shared by multiple `SyntaxKind`s~~.
This PR:
- Changes the wrapped type for `TokenSet` from `u128` to `[u64; 3]` ~~`[u*; N]` (currently `[u16; 17]`) where `u*` can be any desirable unsigned integer type and `N` is the minimum array length needed to represent all token `SyntaxKind`s without any collisions~~.
- Edit: Add assertion that `TokenSet`s only include token `SyntaxKind`s
- Edit: Add ~7 missing [reserved keywords](https://doc.rust-lang.org/stable/reference/keywords.html#reserved-keywords)
- ~~Moves the definition of the `TokenSet` type to grammar codegen in xtask, so that `N` is adjusted automatically (depending on the chosen `u*` "base" type) when new `SyntaxKind`s are added~~.
- ~~Updates the `token_set_works_for_tokens` unit test to include the `__LAST` `SyntaxKind` as a way of catching overflows in tests.~~
~~Currently `u16` is arbitrarily chosen as the `u*` "base" type mostly because it strikes a good balance (IMO) between unused bits and readability of the generated `TokenSet` code (especially the [`union` method](7a8374c162/crates/parser/src/token_set.rs (L26-L28))), but I'm open to other suggestions or a better methodology for choosing `u*` type.~~
~~I considered using a third-party crate for the bit-set, but a direct implementation seems simple enough without adding any new dependencies. I'm not strongly opposed to using a third-party crate though, if that's preferred.~~
~~Finally, I haven't had the chance to review issues, to figure out if there are any parser issues caused by collisions due the current implementation that may be fixed by this PR - I just stumbled upon the issue while adding "new" keywords to solve #16858~~
Edit: fixes#16858