show in docs whether the return type of a function impls Iterator/Read/Write
Closes#25928
This PR makes it so that when rustdoc documents a function, it checks the return type to see whether it implements a handful of specific traits. If so, it will print the impl and any associated types. Rather than doing this via a whitelist within rustdoc, i chose to do this by a new `#[doc]` attribute parameter, so things like `Future` could tap into this if desired.
### Known shortcomings
~~The printing of impls currently uses the `where` class over the whole thing to shrink the font size relative to the function definition itself. Naturally, when the impl has a where clause of its own, it gets shrunken even further:~~ (This is no longer a problem because the design changed and rendered this concern moot.)
The lookup currently just looks at the top-level type, not looking inside things like Result or Option, which renders the spotlights on Read/Write a little less useful:
<details><summary>`File::{open, create}` don't have spotlight info (pic of old design)</summary>
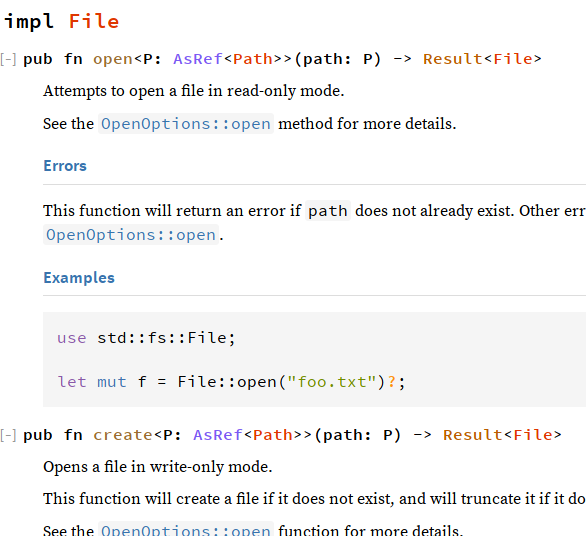
</details>
All three of the initially spotlighted traits are generically implemented on `&mut` references. Rustdoc currently treats a `&mut T` reference-to-a-generic as an impl on the reference primitive itself. `&mut Self` counts as a generic in the eyes of rustdoc. All this combines to create this lovely scene on `Iterator::by_ref`:
<details><summary>`Iterator::by_ref` spotlights Iterator, Read, and Write (pic of old design)</summary>
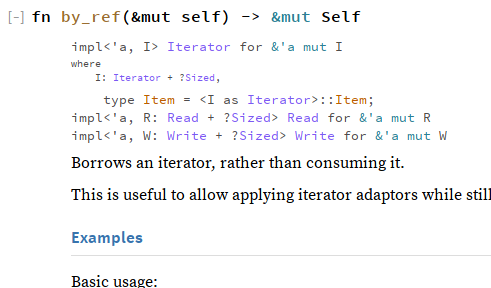
</details>
This is the core method in terms of which the other methods (fold, all, any, find, position, nth, ...) can be implemented, allowing Iterator implementors to get the full goodness of internal iteration by only overriding one method (per direction).
Improve wording for StepBy
No other iterator makes the distinction between an iterator and an iterator adapter
in its summary line, so change it to be consistent with all other adapters.
Add blanket TryFrom impl when From is implemented.
Adds `impl<T, U> TryFrom<T> for U where U: From<T>`.
Removes `impl<'a, T> TryFrom<&'a str> for T where T: FromStr` (originally added in #40281) due to overlapping impls caused by the new blanket impl. This removal is to be discussed further on the tracking issue for TryFrom.
Refs #33417.
/cc @sfackler, @scottmcm (thank you for the help!), and @aturon
Add more custom folding to `core::iter` adaptors
Many of the iterator adaptors will perform faster folds if they forward
to their inner iterator's folds, especially for inner types like `Chain`
which are optimized too. The following types are newly specialized:
| Type | `fold` | `rfold` |
| ----------- | ------ | ------- |
| `Enumerate` | ✓ | ✓ |
| `Filter` | ✓ | ✓ |
| `FilterMap` | ✓ | ✓ |
| `FlatMap` | exists | ✓ |
| `Fuse` | ✓ | ✓ |
| `Inspect` | ✓ | ✓ |
| `Peekable` | ✓ | N/A¹ |
| `Skip` | ✓ | N/A² |
| `SkipWhile` | ✓ | N/A¹ |
¹ not a `DoubleEndedIterator`
² `Skip::next_back` doesn't pull skipped items at all, but this couldn't
be avoided if `Skip::rfold` were to call its inner iterator's `rfold`.
Benchmarks
----------
In the following results, plain `_sum` computes the sum of a million
integers -- note that `sum()` is implemented with `fold()`. The
`_ref_sum` variants do the same on a `by_ref()` iterator, which is
limited to calling `next()` one by one, without specialized `fold`.
The `chain` variants perform the same tests on two iterators chained
together, to show a greater benefit of forwarding `fold` internally.
test iter::bench_enumerate_chain_ref_sum ... bench: 2,216,264 ns/iter (+/- 29,228)
test iter::bench_enumerate_chain_sum ... bench: 922,380 ns/iter (+/- 2,676)
test iter::bench_enumerate_ref_sum ... bench: 476,094 ns/iter (+/- 7,110)
test iter::bench_enumerate_sum ... bench: 476,438 ns/iter (+/- 3,334)
test iter::bench_filter_chain_ref_sum ... bench: 2,266,095 ns/iter (+/- 6,051)
test iter::bench_filter_chain_sum ... bench: 745,594 ns/iter (+/- 2,013)
test iter::bench_filter_ref_sum ... bench: 889,696 ns/iter (+/- 1,188)
test iter::bench_filter_sum ... bench: 667,325 ns/iter (+/- 1,894)
test iter::bench_filter_map_chain_ref_sum ... bench: 2,259,195 ns/iter (+/- 353,440)
test iter::bench_filter_map_chain_sum ... bench: 1,223,280 ns/iter (+/- 1,972)
test iter::bench_filter_map_ref_sum ... bench: 611,607 ns/iter (+/- 2,507)
test iter::bench_filter_map_sum ... bench: 611,610 ns/iter (+/- 472)
test iter::bench_fuse_chain_ref_sum ... bench: 2,246,106 ns/iter (+/- 22,395)
test iter::bench_fuse_chain_sum ... bench: 634,887 ns/iter (+/- 1,341)
test iter::bench_fuse_ref_sum ... bench: 444,816 ns/iter (+/- 1,748)
test iter::bench_fuse_sum ... bench: 316,954 ns/iter (+/- 2,616)
test iter::bench_inspect_chain_ref_sum ... bench: 2,245,431 ns/iter (+/- 21,371)
test iter::bench_inspect_chain_sum ... bench: 631,645 ns/iter (+/- 4,928)
test iter::bench_inspect_ref_sum ... bench: 317,437 ns/iter (+/- 702)
test iter::bench_inspect_sum ... bench: 315,942 ns/iter (+/- 4,320)
test iter::bench_peekable_chain_ref_sum ... bench: 2,243,585 ns/iter (+/- 12,186)
test iter::bench_peekable_chain_sum ... bench: 634,848 ns/iter (+/- 1,712)
test iter::bench_peekable_ref_sum ... bench: 444,808 ns/iter (+/- 480)
test iter::bench_peekable_sum ... bench: 317,133 ns/iter (+/- 3,309)
test iter::bench_skip_chain_ref_sum ... bench: 1,778,734 ns/iter (+/- 2,198)
test iter::bench_skip_chain_sum ... bench: 761,850 ns/iter (+/- 1,645)
test iter::bench_skip_ref_sum ... bench: 478,207 ns/iter (+/- 119,252)
test iter::bench_skip_sum ... bench: 315,614 ns/iter (+/- 3,054)
test iter::bench_skip_while_chain_ref_sum ... bench: 2,486,370 ns/iter (+/- 4,845)
test iter::bench_skip_while_chain_sum ... bench: 633,915 ns/iter (+/- 5,892)
test iter::bench_skip_while_ref_sum ... bench: 666,926 ns/iter (+/- 804)
test iter::bench_skip_while_sum ... bench: 444,405 ns/iter (+/- 571)
Many of the iterator adaptors will perform faster folds if they forward
to their inner iterator's folds, especially for inner types like `Chain`
which are optimized too. The following types are newly specialized:
| Type | `fold` | `rfold` |
| ----------- | ------ | ------- |
| `Enumerate` | ✓ | ✓ |
| `Filter` | ✓ | ✓ |
| `FilterMap` | ✓ | ✓ |
| `FlatMap` | exists | ✓ |
| `Fuse` | ✓ | ✓ |
| `Inspect` | ✓ | ✓ |
| `Peekable` | ✓ | N/A¹ |
| `Skip` | ✓ | N/A² |
| `SkipWhile` | ✓ | N/A¹ |
¹ not a `DoubleEndedIterator`
² `Skip::next_back` doesn't pull skipped items at all, but this couldn't
be avoided if `Skip::rfold` were to call its inner iterator's `rfold`.
Benchmarks
----------
In the following results, plain `_sum` computes the sum of a million
integers -- note that `sum()` is implemented with `fold()`. The
`_ref_sum` variants do the same on a `by_ref()` iterator, which is
limited to calling `next()` one by one, without specialized `fold`.
The `chain` variants perform the same tests on two iterators chained
together, to show a greater benefit of forwarding `fold` internally.
test iter::bench_enumerate_chain_ref_sum ... bench: 2,216,264 ns/iter (+/- 29,228)
test iter::bench_enumerate_chain_sum ... bench: 922,380 ns/iter (+/- 2,676)
test iter::bench_enumerate_ref_sum ... bench: 476,094 ns/iter (+/- 7,110)
test iter::bench_enumerate_sum ... bench: 476,438 ns/iter (+/- 3,334)
test iter::bench_filter_chain_ref_sum ... bench: 2,266,095 ns/iter (+/- 6,051)
test iter::bench_filter_chain_sum ... bench: 745,594 ns/iter (+/- 2,013)
test iter::bench_filter_ref_sum ... bench: 889,696 ns/iter (+/- 1,188)
test iter::bench_filter_sum ... bench: 667,325 ns/iter (+/- 1,894)
test iter::bench_filter_map_chain_ref_sum ... bench: 2,259,195 ns/iter (+/- 353,440)
test iter::bench_filter_map_chain_sum ... bench: 1,223,280 ns/iter (+/- 1,972)
test iter::bench_filter_map_ref_sum ... bench: 611,607 ns/iter (+/- 2,507)
test iter::bench_filter_map_sum ... bench: 611,610 ns/iter (+/- 472)
test iter::bench_fuse_chain_ref_sum ... bench: 2,246,106 ns/iter (+/- 22,395)
test iter::bench_fuse_chain_sum ... bench: 634,887 ns/iter (+/- 1,341)
test iter::bench_fuse_ref_sum ... bench: 444,816 ns/iter (+/- 1,748)
test iter::bench_fuse_sum ... bench: 316,954 ns/iter (+/- 2,616)
test iter::bench_inspect_chain_ref_sum ... bench: 2,245,431 ns/iter (+/- 21,371)
test iter::bench_inspect_chain_sum ... bench: 631,645 ns/iter (+/- 4,928)
test iter::bench_inspect_ref_sum ... bench: 317,437 ns/iter (+/- 702)
test iter::bench_inspect_sum ... bench: 315,942 ns/iter (+/- 4,320)
test iter::bench_peekable_chain_ref_sum ... bench: 2,243,585 ns/iter (+/- 12,186)
test iter::bench_peekable_chain_sum ... bench: 634,848 ns/iter (+/- 1,712)
test iter::bench_peekable_ref_sum ... bench: 444,808 ns/iter (+/- 480)
test iter::bench_peekable_sum ... bench: 317,133 ns/iter (+/- 3,309)
test iter::bench_skip_chain_ref_sum ... bench: 1,778,734 ns/iter (+/- 2,198)
test iter::bench_skip_chain_sum ... bench: 761,850 ns/iter (+/- 1,645)
test iter::bench_skip_ref_sum ... bench: 478,207 ns/iter (+/- 119,252)
test iter::bench_skip_sum ... bench: 315,614 ns/iter (+/- 3,054)
test iter::bench_skip_while_chain_ref_sum ... bench: 2,486,370 ns/iter (+/- 4,845)
test iter::bench_skip_while_chain_sum ... bench: 633,915 ns/iter (+/- 5,892)
test iter::bench_skip_while_ref_sum ... bench: 666,926 ns/iter (+/- 804)
test iter::bench_skip_while_sum ... bench: 444,405 ns/iter (+/- 571)
No other iterator makes the distinction between an iterator and an iterator adapter
in its summary line, so change it to be consistent with all other adapters.
This verifies that TrustedRandomAccess has no side effects when the
iterator item implements Copy. This also implements TrustedLen and
TrustedRandomAccess for str::Bytes.
Add iterator method .rfold(init, function); the reverse of fold
rfold is the reverse version of fold.
Fold allows iterators to implement a different (non-resumable) internal
iteration when it is more efficient than the external iteration implemented
through the next method. (Common examples are VecDeque and .chain()).
Introduce rfold() so that the same customization is available for reverse
iteration. This is achieved by both adding the method, and by having the
Rev\<I> adaptor connect Rev::rfold → I::fold and Rev::fold → I::rfold.
On the surface, rfold(..) is just .rev().fold(..), but the special case
implementations allow a data structure specific fold to be used through for
example .iter().rev(); we thus have gains even for users never calling exactly
rfold themselves.
rfold is the reverse version of fold.
Fold allows iterators to implement a different (non-resumable) internal
iteration when it is more efficient than the external iteration
implemented through the next method. (Common examples are VecDeque and
.chain()).
Introduce rfold() so that the same customization is available for
reverse iteration. This is achieved by both adding the method, and by
having the Rev<I> adaptor connect Rev::rfold -> I::fold, Rev::fold -> I::rfold.
Adaptors are things that take iterators and adapt them into other
iterators. With this definition, fold is just a usual method, because it
doesn't normally make an iterator.
stabilized iterator_for_each (closes#42986)
Also updated clippy and rls as these use the iterator_for_each
I've made my first PR's today so most likely I've done something wrong. Sorry about that!
`FlatMap` can use internal iteration for its `fold`, which shows a
performance advantage in the new benchmarks:
test iter::bench_flat_map_chain_ref_sum ... bench: 4,354,111 ns/iter (+/- 108,871)
test iter::bench_flat_map_chain_sum ... bench: 468,167 ns/iter (+/- 2,274)
test iter::bench_flat_map_ref_sum ... bench: 449,616 ns/iter (+/- 6,257)
test iter::bench_flat_map_sum ... bench: 348,010 ns/iter (+/- 1,227)
... where the "ref" benches are using `by_ref()` that isn't optimized.
So this change shows a decent advantage on its own, but much more when
combined with a `chain` iterator that also optimizes `fold`.
Adds `impl<T, U> TryFrom<T> for U where U: From<T>`.
Removes `impl<'a, T> TryFrom<&'a str> for T where T: FromStr` due to
overlapping impls caused by the new blanket impl. This removal is to
be discussed further on the tracking issue for TryFrom.
Refs #33417.
Add an overflow check in the Iter::next() impl for Range<_> to help with vectorization.
This helps with vectorization in some cases, such as (0..u16::MAX).collect::<Vec<u16>>(),
as LLVM is able to change the loop condition to use equality instead of less than and should help with #43124. (See also my [last comment](https://github.com/rust-lang/rust/issues/43124#issuecomment-319098625) there.) This PR makes collect on ranges of u16, i16, i8, and u8 **significantly** faster (at least on x86-64 and i686), and pretty close, though not quite equivalent to a [manual unsafe implementation](https://is.gd/nkoecB). 32 ( and 64-bit values on x86-64) bit values were already vectorized without this change, and they still are. This PR doesn't seem to help with 64-bit values on i686, as they still don't vectorize well compared to doing a manual loop.
I'm a bit unsure if this was the best way of implementing this, I tried to do it with as little changes as possible and avoided changing the step trait and the behavior in RangeFrom (I'll leave that for others like #43127 to discuss wider changes to the trait). I tried simply changing the comparison to `self.start != self.end` though that made the compiler segfault when compiling stage0, so I went with this method instead for now.
As for `next_back()`, reverse ranges seem to optimise properly already.
This helps with vectorization in some cases, such as (0..u16::MAX).collect::<Vec<u16>>(),
as LLVM is able to change the loop condition to use equality instead of less than
Add `Iterator::for_each`
This works like a `for` loop in functional style, applying a closure to
every item in the `Iterator`. It doesn't allow `break`/`continue` like
a `for` loop, nor any other control flow outside the closure, but it may
be a more legible style for tying up the end of a long iterator chain.
This was tried before in #14911, but nobody made the case for using it
with longer iterators. There was also `Iterator::advance` at that time
which was more capable than `for_each`, but that no longer exists.
The `itertools` crate has `Itertools::foreach` with the same behavior,
but thankfully the names won't collide. The `rayon` crate also has a
`ParallelIterator::for_each` where simple `for` loops aren't possible.
> I really wish we had `for_each` on seq iterators. Having to use a
> dummy operation is annoying. - [@nikomatsakis][1]
[1]: https://github.com/nikomatsakis/rayon/pull/367#issuecomment-308455185
Replaced by adding extra imports, adding hidden code (`# ...`), modifying
examples to be runnable (sorry Homura), specifying non-Rust code, and
converting to should_panic, no_run, or compile_fail.
Remaining "```ignore"s received an explanation why they are being ignored.
{kind=link}
{kind=link}