Fix capture analysis for by-move closure bodies
The check we were doing to figure out if a coroutine was borrowing from its parent coroutine-closure was flat-out wrong -- a misunderstanding of mine of the way that `tcx.closure_captures` represents its captures.
Fixes#123251 (the miri/ui test I added should more than cover that issue)
r? `@oli-obk` -- I recognize that this PR may be underdocumented, so please ask me what I should explain further.
rename ptr::from_exposed_addr -> ptr::with_exposed_provenance
As discussed on [Zulip](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-opsem/topic/To.20expose.20or.20not.20to.20expose/near/427757066).
The old name, `from_exposed_addr`, makes little sense as it's not the address that is exposed, it's the provenance. (`ptr.expose_addr()` stays unchanged as we haven't found a better option yet. The intended interpretation is "expose the provenance and return the address".)
The new name nicely matches `ptr::without_provenance`.
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
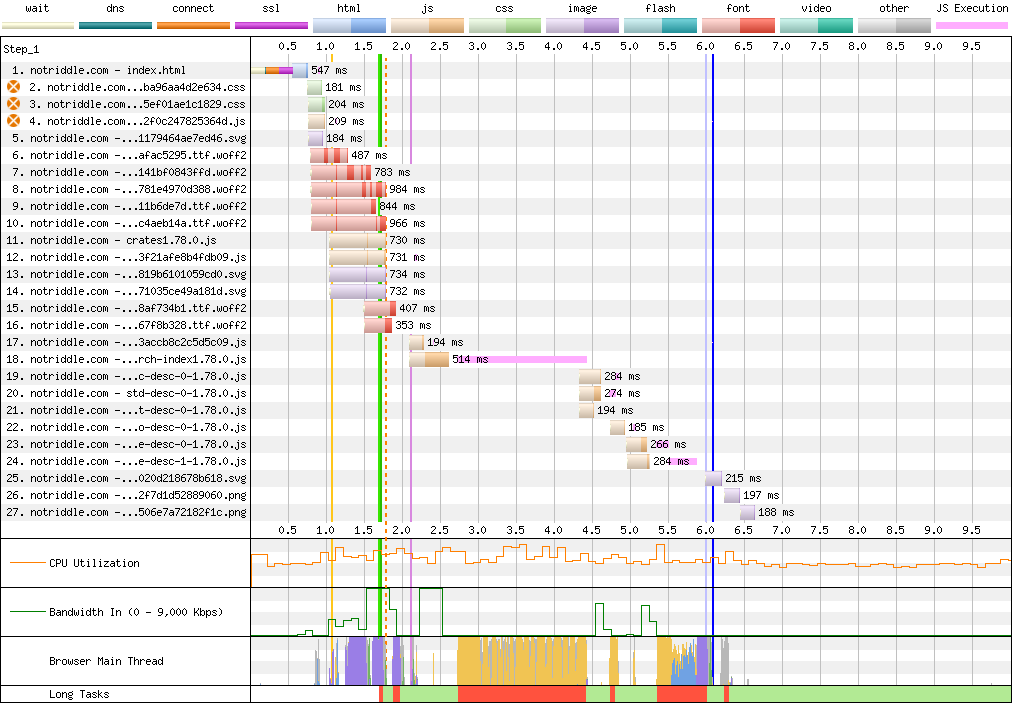
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
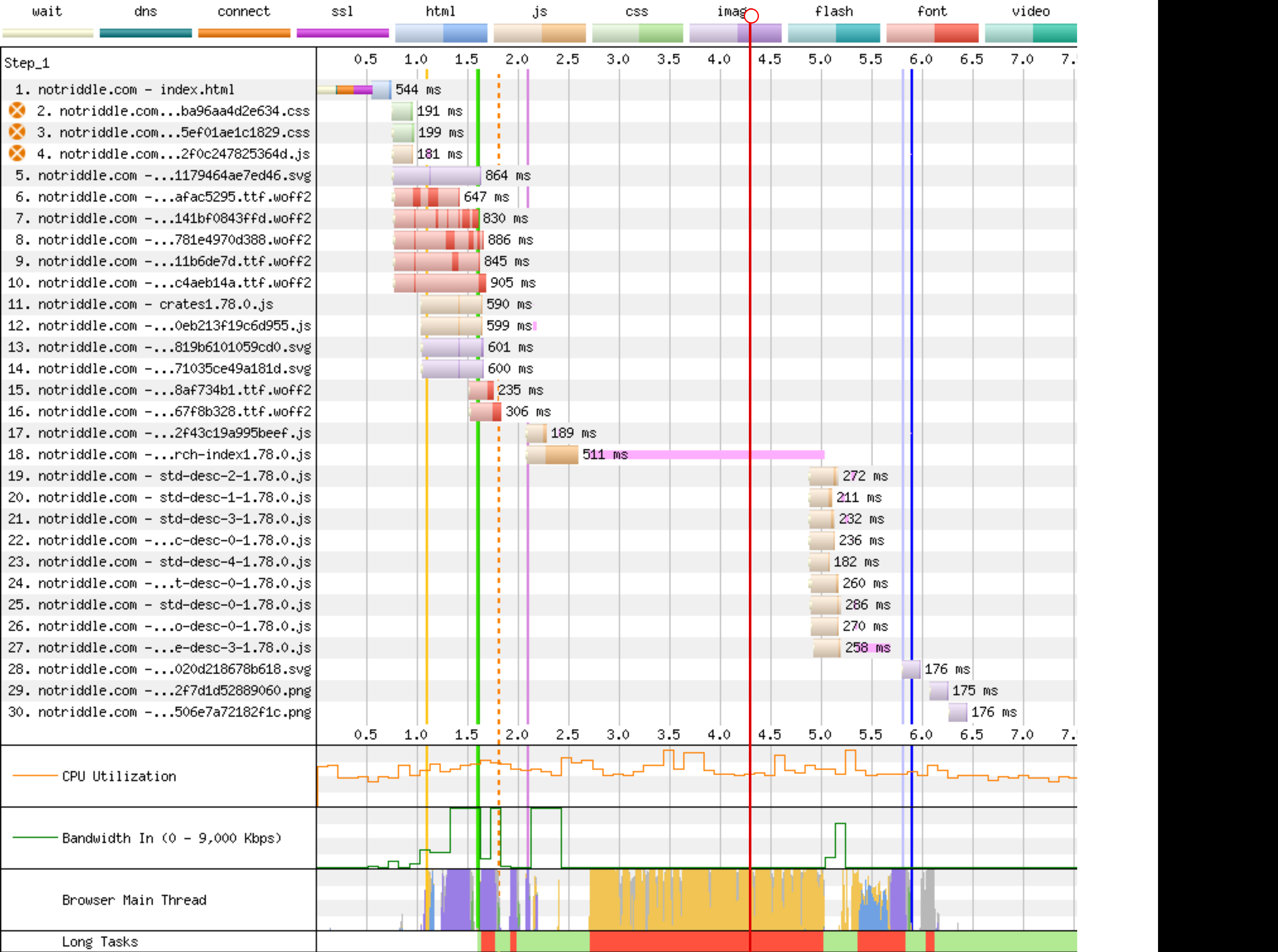
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
Refactor the way bootstrap invokes `cargo miri`
Instead of basically doing `cargo run --manifest-path=<cargo-miri's manifest> -- miri`, let's invoke the `cargo-miri` binary directly. That means less indirections, and also makes it easier to e.g. run the libcore test suite in Miri. (But there are still other issues with that.)
Also also adjusted Miri's stage numbering so that it is consistent with rustc/rustdoc.
This also makes `./x.py test miri` honor `--no-doc`.
And this fixes https://github.com/rust-lang/rust/issues/123177 by moving where we handle parallel_compiler.
Rewrite `core-no-fp-fmt-parse` test in Rust
Claiming the simple "core-no-fp-fmt-parse" test from #121876. `run_make_support` was altered with `arg_path` written in #121918 by `@abhay-51,` with additional doc comment.
Preliminary GSoC contribution for the project proposal mentored by `@jieyouxu.`
Make source tarball generation more reproducible
This PR performs several changes to source tarball generation (`x dist rustc-src`) in order to make it more reproducible (in light of the recent "xz backdoor"...). I want to follow up on it with making a separate CI workflow for generating the tarball.
After this PR, running this locally produces identical checksums:
```bash
$ ./x dist rustc-src
$ sha256sum build/dist/rustc-1.79.0-src.tar.gz
$ ./x dist rustc-src
$ sha256sum build/dist/rustc-1.79.0-src.tar.gz
```
r? `@Mark-Simulacrum`
make some doc comments not doc tests
`./miri test --doc` will run doctests even if we have them disabled (that's a cargo quirk: https://github.com/rust-lang/cargo/issues/13668). This fixes that command to not fail.
compiletest: print reason for failing to read tests
Turns this
```
Could not read tests from /path/to/rust/tests/run-make
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Build completed unsuccessfully in 0:00:05
```
into this:
```
Could not read tests from /path/to/rust/tests/run-make: run-make tests cannot have both `Makefile` and `rmake.rs`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Build completed unsuccessfully in 0:00:05
```
While first one is technically correct - it's not helpful at all, adding backtrace is not making it any better.
Stabilize `unchecked_{add,sub,mul}`
Tracking issue: #85122
I think we might as well just stabilize these basic three. They're the ones that have `nuw`/`nsw` flags in LLVM.
Notably, this doesn't include the potentially-more-complex or -more-situational things like `unchecked_neg` or `unchecked_shr` that are under different feature flags.
To quote Ralf https://github.com/rust-lang/rust/issues/85122#issuecomment-1681669646,
> Are there any objections to stabilizing at least `unchecked_{add,sub,mul}`? For those there shouldn't be any surprises about what their safety requirements are.
*Semantially* these are [already available on stable, even in `const`, via](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=bdb1ff889b61950897f1e9f56d0c9a36) `checked_*`+`unreachable_unchecked`. So IMHO we might as well just let people write them directly, rather than try to go through a `let Some(x) = x.checked_add(y) else { unsafe { hint::unreachable_unchecked() }};` dance.
I added additional text to each method to attempt to better describe the behaviour and encourage `wrapping_*` instead.
r? rust-lang/libs-api
Match ergonomics 2024: implement mutable by-reference bindings
Implements the mutable by-reference bindings portion of match ergonomics 2024 (#123076), with the `mut ref`/`mut ref mut` syntax, under feature gate `mut_ref`.
r? `@Nadrieril`
`@rustbot` label A-patterns A-edition-2024
Codegen const panic messages as function calls
This skips emitting extra arguments at every callsite (of which there
can be many). For a librustc_driver build with overflow checks enabled,
this cuts 0.7MB from the resulting shared library (see [perf]).
A sample improvement from nightly:
```
leaq str.0(%rip), %rdi
leaq .Lalloc_d6aeb8e2aa19de39a7f0e861c998af13(%rip), %rdx
movl $25, %esi
callq *_ZN4core9panicking5panic17h17cabb89c5bcc999E@GOTPCREL(%rip)
```
to this PR:
```
leaq .Lalloc_d6aeb8e2aa19de39a7f0e861c998af13(%rip), %rdi
callq *_RNvNtNtCsduqIKoij8JB_4core9panicking11panic_const23panic_const_div_by_zero@GOTPCREL(%rip)
```
[perf]: https://perf.rust-lang.org/compare.html?start=a7e4de13c1785819f4d61da41f6704ed69d5f203&end=64fbb4f0b2d621ff46d559d1e9f5ad89a8d7789b&stat=instructions:u
Use compiletest directives instead of manually checking TARGET / tools
Changes:
- Accept `ignore-wasm32-wasip1` and `needs-wasmtime` directives.
- Add support for needing `wasmtime` as a runner.
- Update wasm/compiler_builtin tests to use compiletest directives over manual checks.